
一放出就在7个Zero-Shot任务上取得SOTA,其强大的文本生成能力让人震惊,直接弥补了BERT文本生成的缺陷,甚至连它的创造者们 OpenAI 也发言表示“Too Dangerous To Release(太危险了不能公开)”,结果在社交媒体上引起了一片争论:有挺OpenAI派表示应该对这种模型进行限制,也有反OpenAI派表示就是炒作,“放出来估计也没啥事”。
当然,这一系列的争论最终的受益者无疑是OpenAI ,可算是一整年出尽了风头,从二月到去年十一月都有GPT2的持续报道。
消停了半年,上周,OpenAI 又放了个大招:GPT3突然放出。文摘菌的朋友圈瞬间被刷爆,reddit上也进行了激烈讨论。
GPT3之所以能引起这么大关注,首先当然是爸爸GPT2的功劳。
炒作了整个19年,就那几个模型还悄咪咪地一点点放出来,从年初一直放到年末。当然GPT2本身在生成式的效果也是毋庸置疑的,所以大家也拿着GPT2搞出了各种脑洞大开的应用,比如用它下棋,还有人把它做成一款文字冒险游戏等等。
第二,也是GPT3自身特点有异于正常模型的地方,它非常非常非常大,训练非常非常非常烧钱。大到什么地步呢,相对于之前最大的T-NLG直接提高了一个量级,这是一个什么概念,可以看看下图
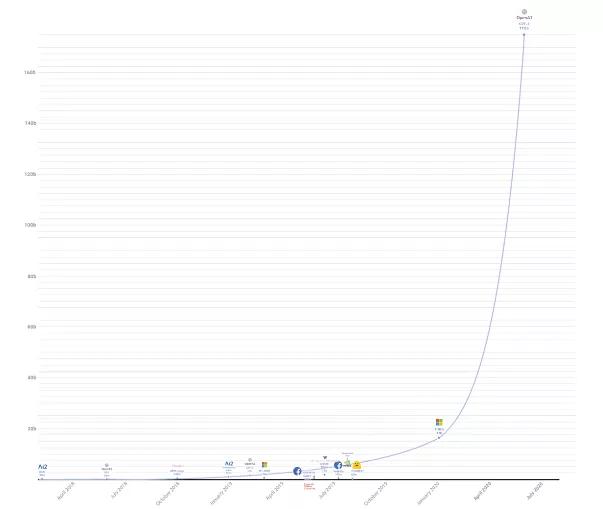
于是,咱们也照猫画虎来给GPT系列做一个这样的提交史,不光能回顾一下GPT的发展史,还能更好理解GPT3模型的细节。
初步提交:GPT
- Transformer 编码器
模型: 0.11B参数, 12层,768隐层大小,12头,64头大小,512上下文长度
数据:BooksCorpus,1B Word Benchmark
词表:BPE 40000
训练目标:单向语言模型
提交:Improving Language Understanding by Generative Pre-Training
作者:Radford, Alec, et al
日期:Mon June 11 10: 46: 37 2018 0000
里程碑提交:GPT2
模型:1.54B参数, 48层,1600隐层大小,25头,64头大小,1024上下文长度
数据:WebText,抓取 Reddit 上3星以上链接,40GB
词表:50,257
疯狂PR,Too Dangerous Too Release,阶段性饥饿营销
提交:Language Models are Unsupervised Multitask Learners
作者:Radford, Alec, et al.
日期:Thu Feb 14 17: 35: 48 2019 0000
最近提交:GPT3
模型:175B参数, 96层,12288隐层大小,96头,128头大小,2048上下文长度
模型:没说细节的 sparse attention layers
数据:60% Common Crawl (清洗过的),22% WebText2,8% Books1,8% Books2,3% Wikipedia,合计 700 GB
提交:Language Models are Few-Shot Learners
作者:Brown, Tom B., et al.
日期:Thu May 28 15: 43: 40 2020 0000
可以看到GPT3相比起GPT2的变化可能就是给模型增大,数据增多,这和GPT1到GPT2的变化差不多。而从GPT1到GPT2时发生这样的变化还是很值得关注的,因为之前没人知道给单向Transformer语言模型量级提高很大,再用高质量语料来训,就能获得很好的生成模型。这也是为什么GPT都没啥人关注,直到被BERT点名出来吊打,才有人知道有GPT这东西,一看还就只是一个Transformer解码器。
那么 GPT3值得关注的地方到底在什么地方呢,那就在它厚厚的实验分析和细节内容里了。
总结一下目前对于GPT3持赞同和反对态度的两方意见,接下来文摘菌带大家详细看看这个模型的优劣势。
正方:不失美味!整体表现出的泛化性很有价值对于GPT3全面的实验分析,大部分人还是买账的。
特别GPT3主要在三个设定下进行的大量 NLP 实验,其中包括Zero-Shot(没有样本,只是在上下文给出一段自然语言描述),One-shot(在上下文中给出一个样本),还有Few-Shot(在上下文中给出一些样本)。而一般大家比较关心的预训练模型精调,论文里根本都没怎么做,直接留给未来研究了。

之后一个很有意思的点是,GPT2就已经有提到过的,生成虚假文本的实验。论文中发现当模型参数量提高到175B这个量级时,人们基本上就不太能分别出是一条新闻是GPT3生成的还是真正的新闻了。看图上就能看到50%相当于蒙着眼瞎猜,而GPT3则差不多52-53%左右,对比起来GPT2体量的差不多在62-63%左右。
这样的结论无疑让之前就引起的GPT2生成虚假信息担心更加剧,因此文中也对GPT2放出一年后,其被用于散播虚假信息相关进行了分析。结果发现当然不是最早说的 “Too Dangerous Too Release“,即使放出来也没发生什么大事,因为GPT2可控生成太难了。当然文中,也提到现在语言模型已经强到这个地步,真的要用起来也只是时间问题,怎么找到更好方法利用强大的生成能力。
除了上面两点,GPT3最让人impressive的还是它整体表现出来的泛化性,其中无论是Zero-Shot,One-Shot,还是Few-Shot,都没有任何训练过程。
也就是说实际测试中,完全在训练没看过的数据上进行预测,而同时还能表现出来一定性能。而且它展示出只要提高模型大小,这个过程可能还没到个头。这就不尽让人开始想,如果继续不断增大,是不是最终能够达到人类的泛化性。
最近微软又给OpenAI造了台超级计算机,恐怕OpenAI还要一条路走到黑。不过这也非常有意思,可以实际验证一下The Bitter Lesson,还有语言模型通往智能的极限。
反方:好像吞了一盘蜡烛,没给AI底层技术带来任何推动当然,既然有看完浮想联翩的,也有看完GPT3失望无比的:什么玩意儿,又没有什么大的创新,得出的结论也是大家差不多都知道的,简直味如嚼蜡。

其中最重要的一点,GPT3相比起GPT2没有什么本质上的突破,模型架构还是一样,训练目标也都一样。变化的只是模型大小,数据多少,而这些在这个后BERT时代并不是什么新奇创举。当然在GPT2的时候还是很让人感到很新鲜,因为没什么人这么做。
GPT3这样并没有给AI底层技术带来任何推动,毫无疑问让人看得很乏味。
打个比方就是,比如某些石油大国很有钱,可以投入很多钱和工程能力去修超级高楼,虽然刷新了最高楼记录,但对于修楼技术可能并没带来什么推动,也没有人会质疑没有修出这个高楼的美国就没有能力去修。
这种单纯的堆量级而带来的所谓SOTA提高,意义不大,反而会让人忽视很多更底层值得去研究的问题。
最近就有文章指出,很多引人注目的AI领域进展其实都是虚的。比如今年MLSys对81种剪枝算法调研发现,十年间可能并没有什么提升。还有去年关于搜索引擎中信息检索算法调研发现,真正里程碑其实在2009年就提出。此外最近一篇关于损失函数对比的论文发现,准确率自2006年其实就没有提高。
同样的,如果从模型架构,损失函数,优化策略来看GPT3,难免会感到失望,因为几乎没有太多变化。况且在GTP2这么高调的情况下,对GPT3期望也不免过高。
此外,还有有些其他点,比如说过度强调参数量级与指标的对比,而没有对few-show这些里面的一些参数K做足够探索,还有GPT3在一些Benchmark上的表现的并不好,比如说在SuperGLUE上。
结语整体来说,我个人对GPT3持有的观点还是比较正向,因为研究有很多方向,而GPT3相当于给模型大小这个方向推到了极致,而且它也在验证The Bitter Lesson里提到的观点,一个简单可放大的算法,加上大量算力就可以产生不一样的效果。事实上,它在这篇论文中展示的泛化能力分析,就可以看到这样一种将语言模型推到极致后带来的不同。让人不禁想,再推下去,是否能够真正到达人类级别的泛化力。
虽然很多大牛认为这条所谓AGI路走不太通,所以现在都在提倡自监督学习或神经生物学启发的方法。但这也并不说明这条路的探索是无意义的,即使失败,从中获得的知识也必定有助于找到正确的方向。
至于对GPT3反面的一些观点,这并不只是GPT3这个模型的问题,这是当前整个NLP预训练语言模型时代的问题,大家发现与其一顿操作猛如虎,定睛一看原地杵的提出一些新算法,还不如直接在预训练模型这样基本上能一定保证收益的方向上发力,收益更明显。但这带来的也是算力需求的飙升,只有大实验室和大公司才有钱来研究,而没钱没设备的就只能坐在下面看神仙打架流口水(没错说的就是我)。
但这也有好处,会让那些没资源的小实验室去更深地思考为什么这些技巧架构有用,同时能否想出替代的方法。
此次OpenAI重金砸出GPT3,到底是一桌美味佳肴,还是一碗糠咽菜?你有什么看法,欢迎在评论区讨论~
相关报道:
https://www.lesswrong.com/posts/ZHrpjDc3CepSeeBuE/gpt-3-a-disappointing-paper
https://leogao.dev/2020/05/29/GPT-3-A-Brief-Summary/
https://www.reddit.com/r/MachineLearning/comments/gsivhg/r_language_models_are_fewshot_learners/
https://web.archive.org/web/20200603035349/https://venturebeat.com/2020/06/01/ai-machine-learning-openai-gpt-3-size-isnt-everything/
https://web.archive.org/web/20200529051002/https://www.sciencemag.org/news/2020/05/eye-catching-advances-some-ai-fields-are-not-real
https://www.gwern.net/newsletter/2020/05#
https://dl.acm.org/doi/abs/10.1145/3331184.3331340
相关文章









关于作者

猜你喜欢























