编辑:编辑部
【新智元导读】最差的人类语料,也要胜过AI生成的文本。随着GPT-4、Stable Diffusion和Midjourney的爆火,越来越多的人开始在工作和生活中引入生成式AI技术。
甚至,有人已经开始尝试用AI生成的数据来训练AI了。难道,这就是传说中的「数据永动机」?
然而,来自牛津、剑桥、帝国理工等机构研究人员发现,如果在训练时大量使用AI内容,会引发模型崩溃(model collapse),造成不可逆的缺陷。

论文地址:https://arxiv.org/abs/2306.07899v1
模型崩溃
而最开始提到的「模型崩溃」,就是在给模型投喂了太多来自AI的数据之后,带来的能够影响多代的退化。
也就是,新一代模型的训练数据会被上一代模型的生成数据所污染,从而对现实世界的感知产生错误的理解。
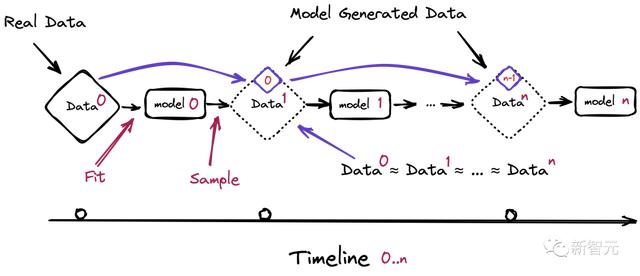
更进一步,这种崩溃还会引发比如基于性别、种族或其他敏感属性的歧视问题,尤其是如果生成AI随着时间的推移学会在其响应中只生成某个种族,而「忘记」其他种族的存在。
而且,除了大语言模型,模型崩溃还会出现在变分自编码器(VAE)、高斯混合模型上。
需要注意的是,模型崩溃的过程与灾难性遗忘(catastrophic forgetting)不同,模型不会忘记以前学过的数据,而是开始把模型的错误想法曲解为现实,并且还会强化自己对错误想法的信念。

举个例子,比如模型在一个包含100张猫图片的数据集上进行训练,其中有10张蓝毛猫,90张黄毛猫。
模型学到的结论是,黄毛猫更普遍,同时会倾向于把蓝毛猫想象的比实际更偏黄,所以在被要求生成新数据时可能会返回一些类似绿毛猫的结果。
而随着时间的推移,蓝毛的原始特征在多个训练epoch中逐渐被侵蚀,直接从蓝色变成了绿色,最终再演变为黄色,这种渐进的扭曲和丢失少数特征的现象就是模型崩溃。

然而,在一些特殊的文本中,这些方法并不能有效执行。比如,在EPFL研究中有ChatGPT合成的10个总结,而GPTZero只检测到6个是合成的。
对此,研究人员通过微调自己的模型来检测AI的使用,发现ChatGPT在编写本文时是最常用的LLM。
对于构建的检测AI数据的方法,研究人员利用原始研究中的答案和用ChatGPT合成的数据,训练了一个定制的「合成-真实分类器」。
然后用这个分类器来估计重新进行的任务中合成答案的普遍性。

具体来讲,研究人员首先使用真正由人类撰写的MTurk回应,和合成LLM生成的回应,来训练特定任务的「合成-真实分类器」。
其次,将这个分类器用于MTurk的真实回应(其中众包人可能使用,也可能没有依赖LLM),以估计LLM使用的普遍性。
最后,研究者确认了结果的有效性,在事后比较分析击键数据与MTurk的回应。
实验结果显示,这个模型在正确识别人工智能文本方面高达99%的准确率。
此外,研究人员用击键数据验证了结果,发现:
- 完全在MTurk文本框中写的总结(不太可能是合成的)都被归类为真实的;
- 在粘贴的总结中,提取式总结和LLM的使用有明显区别。
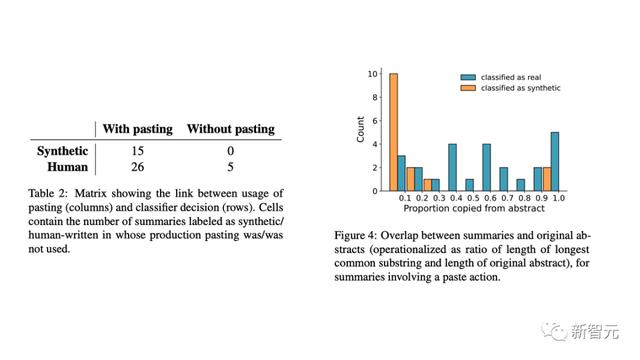
具体来讲,人工智能生成的文本通常与原始总结几乎没有相似之处。这表明AI模型正在生成新文本,而不是复制和粘贴原始内容的一部分。
「人类数据」很重要
现在,人们普遍担心LLM将塑造人类的「信息生态系统」,也就是说,在线可获得的大部分信息都是由LLM生成的。
使用综合生成数据训练的LLM的性能明显降低,就像Ilia Shumailov所称会让模型患上「痴呆症」。

而这个问题将会变得更加严重,因为随着LLM的普及,众包工作者们已经广泛使用ChatGPT等各种LLM。
但对于人类内容创作者来说,这是一个好消息,提高工作效率的同时,还赚到了钱。
但是,若想挽救LLM不陷于崩溃的边缘,还是需要真实的「人类数据」。
1. 人类数据在科学中仍然是至关重要的
2. 在合成数据上训练模型可能会带来偏见和意识形态永久化
3. 随着模型变得流行和更好/多模态,采用率只会增加

总的来说,由人类生成的原始数据可以更好地表示世界,虽然也可能包含某些劣质、概率较低的数据;而生成式模型往往只会过度拟合流行数据,并对概率更低的数据产生误解。
那么,在充斥着生成式AI工具和相关内容的未来,人类制作的内容或许会比今天更有价值,尤其是作为AI原始训练数据的来源。
参考资料:
相关文章









关于作者

猜你喜欢























