编辑:好困
【新智元导读】最近,来自斯坦福的研究人员提出一个基于大语言模型的全新自动评估系统——AlpacaEval。不仅速度快、成本低,而且还经过了2万个人类标注的验证。前段时间,UC伯克利主导的「LLM排位赛」备受圈内关注。
除了各类开源模型外,还有GPT-4、PaLM 2等众多「闭源」模型,甚至还开设了一个「准中文」排行榜。
最近,来自斯坦福的团队,也发布了一款LLM自动评测系统——AlpacaEval,以及对应的AlpacaEval Leaderboard。

在斯坦福的这个排行榜中,GPT-4依然以绝对领先的优势夺得第一,胜率超过了95%。
紧随其后的是,胜率都在80%以上的Claude和chatgpt。其中,Claude以不到3%的优势拿下第二,而ChatGPT则位列第三。
此次获得第四名的,则是一位排位赛新人——微软华人团队发布的WizardLM。
UC伯克利的Vicuna发挥依然稳定,凭借着超过70%的胜率排在第六。
相比之下,斯坦福自己的Alpaca却只排到了第16……
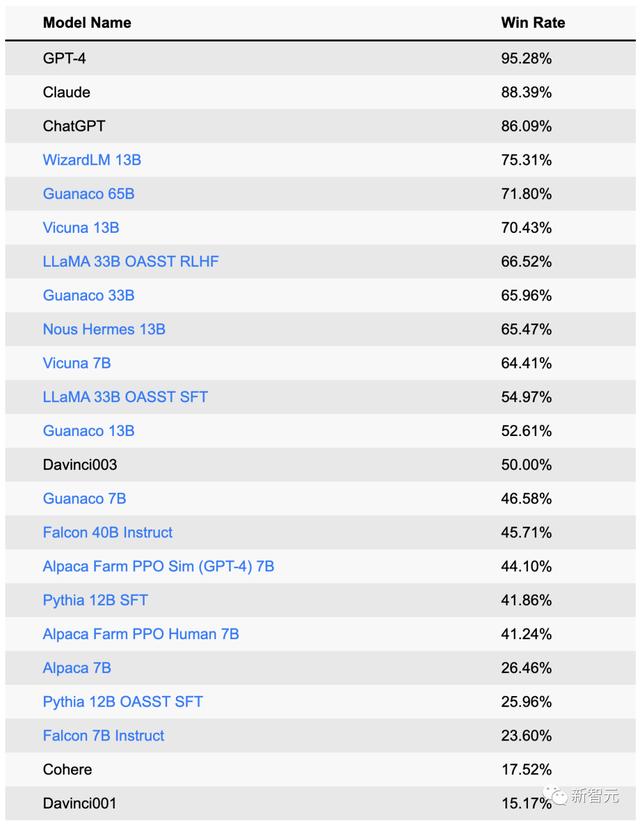
其实,团队自从原始的Alpaca推出以来,已经做了不小的改进——胜率从26%提升到了44%,但依然距离领奖台很远。
对此,其中一位作者有些无奈地表示:「是不是我们哪里做的不对?」

AlpacaEval:易使用、速度快、成本低、经过人类标注验证
AlpacaEval把AlpacaFarm和Aviary进行了结合。一方面使用与AlpacaFarm相同的代码(缓存/随机排列/超参数),另一方面则使用类似于Aviary的排序提示。
与此同时,还对Aviary的提示进行了修改,从而减少对较长输出的偏见。
团队表示,AlpacaEval有着拔群的效果:
与人类多数票的一致性,高于单个人类标注者胜率与人类标注高度相关(0.94)相比于lmsys评测器,有显著提升(从63%提高到69%) 胜率
胜率模型的输出在每个指令上优于text-davinci-003(即参考文本)的比例。
具体而言,首先从AlpacaEval数据集中收集了期望模型在每个指令上的输出对,并将每个输出与相同指令下的参考模型(text-davinci-003)的输出进行配对。
随后,把这些输出同时喂给自动评测器,让它去判断哪一个更好(也就是评测器的偏好)。
最后,将数据集中所有指令的偏好进行平均,从而得到模型相对于text-davinci-003的胜率。如果两个模型打平,那么就算半个偏好。

论文地址:https://arxiv.org/pdf/2305.14387.pdf
标准误差胜率的标准误差(通过N-1进行归一化),即不同指令上的平均偏好。
 不同评测器的对比
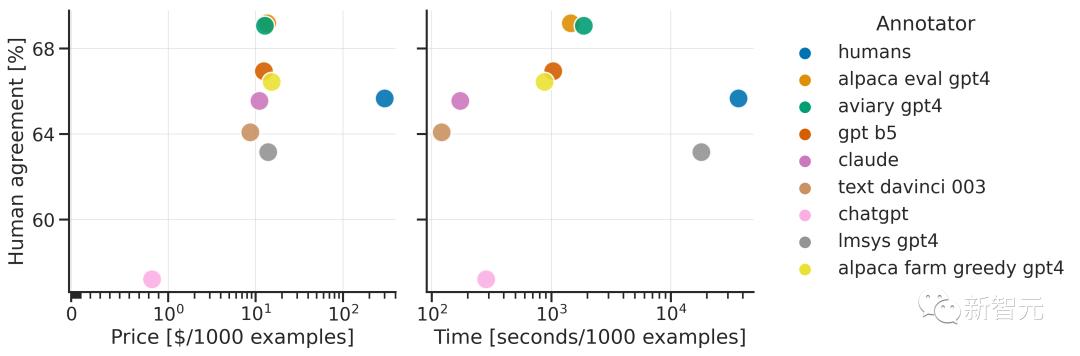
不同评测器的对比团队通过与收集的2.5K个人工标注(每个指令平均包含4个人工标注)进行比较,评测了AlpacaEval数据集上的不同自动标注程序。
下面就是斯坦福的评测器(alpaca_eval_gpt4)、之前的自动评测器(alpaca_farm_greedy_gpt4、aviary_gpt4、lmsys_gpt4)、人类(humans)以及不同基准模型(gpt4、claude、text_davinci_003、guanaco_33b、chatgpt)的测试结果。
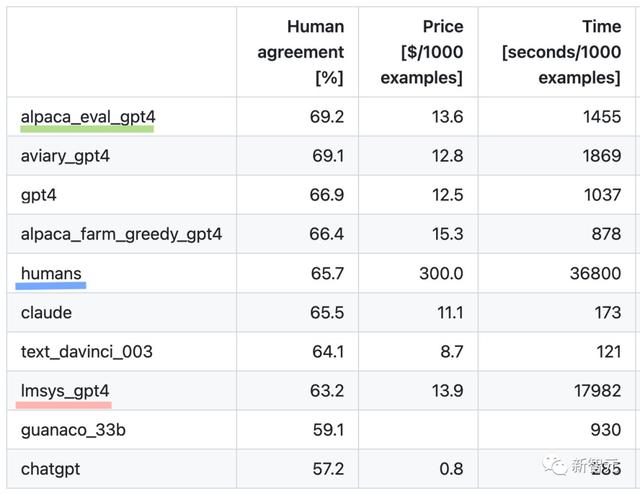 人类一致性:标注者与交叉标注集中人类多数票之间的一致性
人类一致性:标注者与交叉标注集中人类多数票之间的一致性为了估计单个人类标注者(表格中的humans行)与多数人类之间的一致性,首先需要选取一个标注,并计算其在预测其他3个标注的众数时的准确率。
然后,将所有4个标注和650个指令上的准确率求平均,得到人类一致性,即计算预期的(对于人类和样本)留一法一致性。如果众数不唯一,我们随机选择其中一个众数。
对于自动标注器,我们进行完全相同的计算,以便最终的结果可以进行比较。
价格:每1000个标注的平均价格对于人类来说,这是支付众包工人进行这些标注的价格(每小时18美元)。如果价格取决于用于计算标注的机器(例如Guanaco),则将其留空。
时间:计算1000个标注所需的平均时间对于人类来说,这是每个众包工人标注1000个示例所需时间的中位数。
对于自动标注器,这是运行标注所需的平均时间。值得注意的是,这可能取决于不同用户的API限制以及集群正在处理的请求数量。
最后,为了进一步改善自动评测流程,团队发布了:
一个易于定制的流程模型和自动评测器的排行榜分析自动评测器的工具包18K人类标注2K人类交叉标注局限性
虽然AlpacaEval提供了一个有用的比较模型,但它并不是一个全面的的模型能力评测系统,其局限性可以概括为以下三点:
指令比较简单评分时可能更偏向于风格而非事实没有衡量模型可能造成的危害参考资料:
相关文章









关于作者

猜你喜欢























