近期各行各业已进入言必谈 ChatGPT 的阶段,大家津津乐道于 ChatGPT 的各种应用场景,比如怎么在自己的学习或工作中应用,提升效率。就连怎么跟 ChatGPT 提问对话,都发展出一门名为 Prompt Engineering 的新学科分支。
要最大程度地发挥 ChatGPT 的价值,就得对它的原理有一定的了解,这样就能知道它最适用的场景、目前的能力边界等。今天我就用大白话的方式,给大家分享下近期对它的研究和理解。
ChatGPT 和 GPT 是什么关系?简单讲,ChatGPT 是一个产品,GPT 是一个 AI 领域的大语言模型(Large Language Model,简称 LLM)。
ChatGPT 提供了自然语言对话(Chat)的方式,与这个大模型进行交互,得到用户想要的答案。
而大语言模型,你只需要记住它是一种可以对自然语言(也就是平时我们说的各种语言,如中文、英文、日文等)进行处理的程序,它最厉害的地方在于能够基于前面给定的文字,预测接下来可能出现的文本内容。
比如平时你用手机输入法打字或百度搜索,输入“明天天气”,系统就会提示“明天天气怎么样”,就运用了类似的技术。只不过这里的大语言模型,它用来学习和训练的数据量要大非常多,对应的能预测生成的内容也多非常多,可以直接生成一整段话甚至一篇文章。
 Transformer 这个模型为什么厉害?
Transformer 这个模型为什么厉害?Transformer 模型是一种神经网络模型,它可以帮助计算机更好地理解语言,比如翻译句子或者回答问题。相比其他一些经典的神经网络模型(如 RNN、CNN),它的效果更好是因为它有一种自注意力机制(Self-Attention Mechanism)。
这个自注意力机制,可以让模型更好地“注意到”每个单词前后的内容,避免了「只见树木、不见森林」,进而提升对输入的理解程度,提升输出的匹配程度。
举个例子,假如你正在翻译一个句子,传统的方法是一次只翻译一个单词,但是 Transformer 模型可以一次性看到整个句子,然后根据句子中每个单词之间的关系,更好地翻译整个句子。这好比你在阅读一篇故事时,可以看到整个故事,更好地理解故事中的情节。当然实际的模型比这个要复杂得多,以上的例子只是为了便于理解。
另外,自注意力机制支持并行计算,在长内容、需要分步多次计算的处理上也很高效,类似于一个复杂的任务,可以更简单地分解为多个子任务同时进行,所以整体的效率也更高。
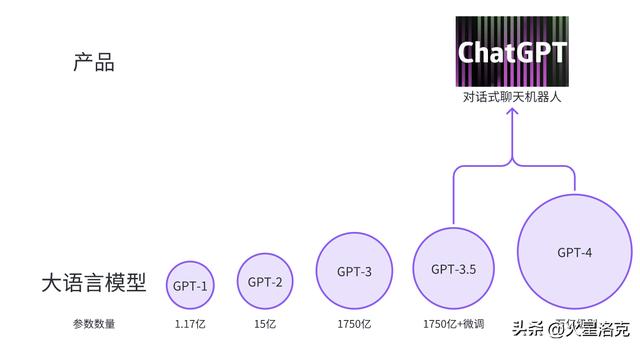
 GPT 目前发展到什么阶段了?
GPT 目前发展到什么阶段了?GPT 的历史发展可以追溯到 2018 年,当时 OpenAI 发布了第一版 GPT 模型,它只有 1.17 亿个参数。后来,OpenAI 又陆续发布了 GPT-2 和 GPT-3 两个版本,今年 3 月 14 日,更是开始在 ChatGPT Plus 用户里,小范围提供 GPT-4 版本。
其中 GPT-3 模型拥有 1750 亿个参数,而 GPT-4 据说有超过一万亿的参数,是目前最大的自然语言处理模型之一。
 怎么最大化地用好 ChatGPT?
怎么最大化地用好 ChatGPT?由于 ChatGPT 底层就是 GPT 模型,它本质上是基于你的输入来匹配一个「概率更高」的输出结果。因此如果你想要充分发挥 ChatGPT 的威力,就要尽可能让模型充分地理解你想要的内容,包括问题的具体要求、预期结果的展现形式等等。这好比找一个人咨询问题,如果你能更充分、明确地描述你想要的,那么就越容易得到结果。
这里分享一个@Rob Lennon 分享的模型,按这几个环节撰写指令,相信你会更容易得到想要的结果。

如果你想更快地抄作业,还可以参考这个开源库的指令示例合集 https://github.com/f/awesome-chatgpt-prompts/blob/main/prompts.csv,里面有大量的例子,相信对你一定有启发。
相关文章









关于作者

猜你喜欢























