它让我看到了未来!AGI离我们又进了一步......
最近关于GPT-3的吹捧在各大社交媒体平台此起彼伏。
GPT-3是谁?它是OpenAI斥巨资打造的自然语言处理模型,拥有1750亿超大参数量,是NLP领域最强AI模型。自今年5月份首次推出以来,凭借惊人的文本生成能力,在各大媒体平台一直热度不减。
这一次,关于GPT-3的吹捧再次被推向高潮,有网友发现 GPT-3不仅能够答题、写文章,做翻译,还能生成代码、做数学推理、数据分析、画图表制作简历,甚至玩游戏都可以,而且效果出奇的好。
由此不禁有网友感叹,如此全能的AI,这是要通往AGI的节奏。不过,过誉的背后也有网友开始质疑,GPT-3真的达到了无所不能的地步了吗?
写代码做UI画图表,50多种新玩法上个月,OpenAI刚刚将GPT-3以API的形式向公众开放,最近就有大批Twitter用户来分享使用体验了,而且好评如潮。据一位Github用户统计, 网友们把这款模型玩出了50多种花样。比如,它可以自动生成SQL查询代码。
例如我们输入“自2020年来有多少用户注册”,就能得到相应的SQL代码,可以看到,代码将时间起点设为2020-01-01,刚好对应“自2020年来”。

UI页面设计。同样只需要输入自然语言即可,模型会根据组件细节描述自动生成。如在这里输入“一一个彩虹色的按钮”。 这里只演示了UI页面的一个组件,包含多个组件、内容、图像的界面也可完成。

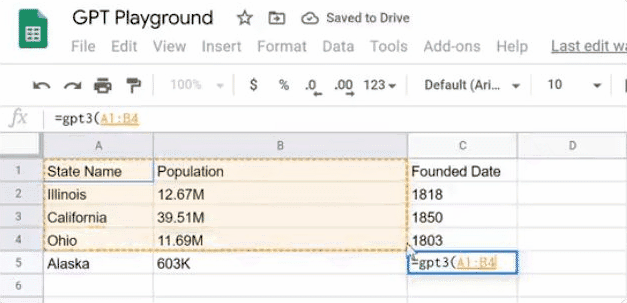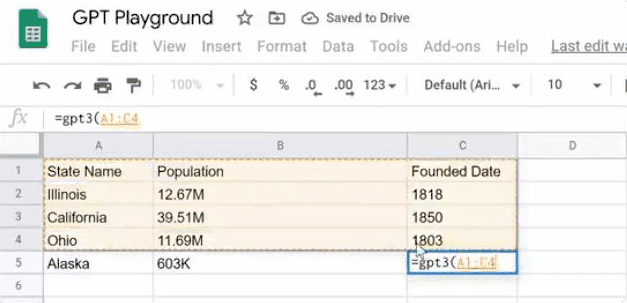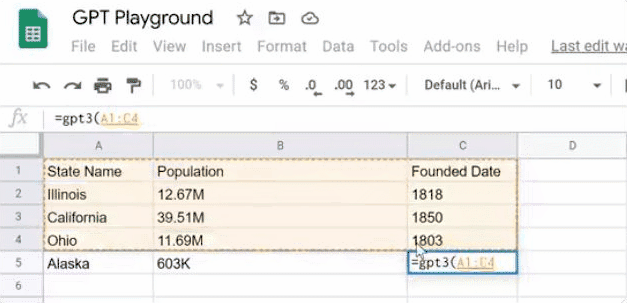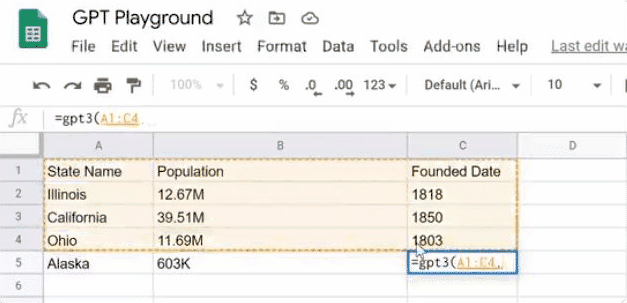
数据搜索和填充。再也不用手动查询,再逐个输入了。如表中GPT-3还可以做人口普查,统计美国各州人数。表格中分别列出了伊利诺伊州、加利福尼亚州、俄亥俄州的人数,应用能据此搜索出密歇根州的人数,以及阿拉斯加州的人数。
Python代码做数据报表。模型会将自然语言转化为Python语言,进而自动识别并将对应内容放在描述的模块中。
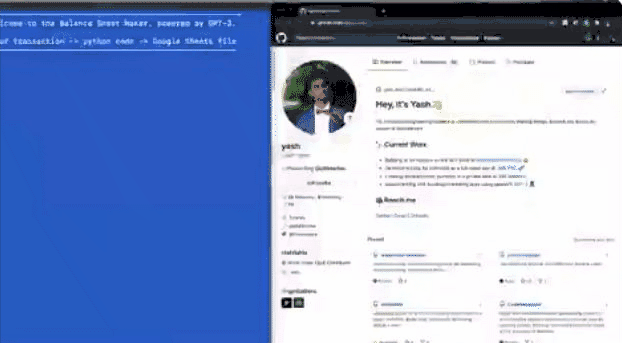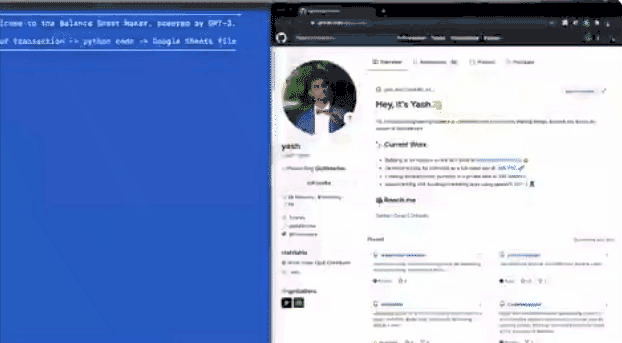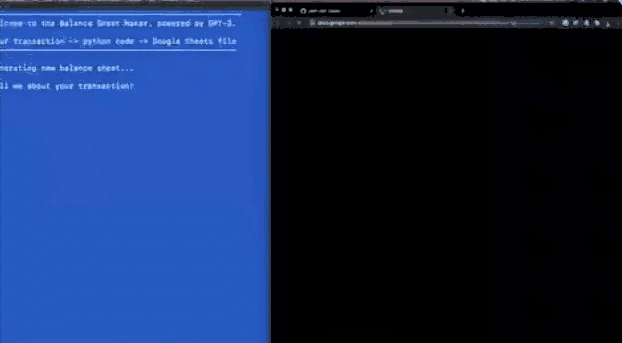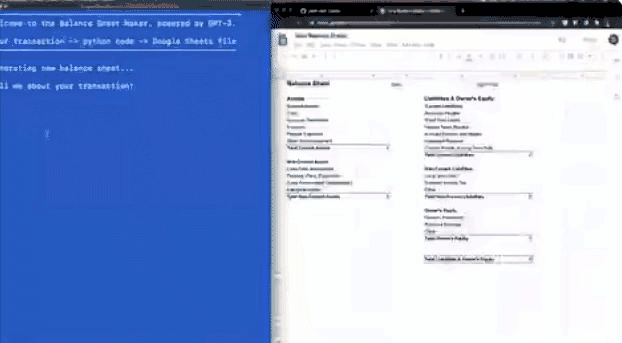
以上只是列举了四个示例,还有Keras代码生成、简历制作、图表绘制等多种功能,具体参加Github链接:https://github.com/elyase/awesome-gpt3#awesome-gpt-3
GPT-3为何如此强大?
在所有NLP模型中,GPT-3在两个方面达到了史无前例的高度,一是参数量,达到了1750亿,比刚推出时世界最大NLP模型Tururing大10倍,比同系列的GPT-2高出116倍。
二是数据集。具体数值很难估计。不过,英语维基百科的全部内容(涵盖约600万篇文章)仅占其训练数据集的0.6%。除此之外,它还涵盖了其他数字化书籍和各种Web链接。
这意味着数据集的文本类型非常丰富,包括新闻报道、诗歌、小说、宗教、科学、生活等等。人类所能查询到的知识领域均在其中。(也可能存在不良内容的风险)
只有通过庞大的知识库的训练,才能把GPT-3培养成一个“全才”,这也是为什么在用户体验中,GPT-3可以不分学科完成所有文本生成任务。
另外,Microsoft和OpenAI合力开发了一款超级计算机,专门用于GPT-3模型训练,这款超级计算机拥有超过 285000 个 CPU 内核、10000 个 GPU 和 400Gbps 的网络连接。它与世界 TOP500 超级计算机相比,位列 Top 5 第五名。

最后一个重要的点是,GPT-3采用了一种Sparse Transfromer模型。
我们知道,Transformer是谷歌研发的一款功能强大的序列模型,最早用在BERT模型中。该模型最大的特点是采用自注意力机制(self-attention)改善了RNN训练慢的缺点。
GPT-3同样采用了 Transformer架构,不同的是它融合了一种稀疏式自注意力机制(Sparse Self-attention Layers),与传统Transfromer模型相比,它可以更好的处理长文档,操作简单,同时在zero-shot和few-shot训练中达到了最佳性能。
在实际运行过程中,它分为预训练和下游任务两个阶段执行。

连常识都不过关,突然就不香了
令人惊讶的是,如此强大的GPT-3,可以玩转50多种任务的模型,可能连基本的常识和简单的数学逻辑都不能通过。一位网友在获得Beta版使用权限后,便对GPT-3进行了图灵测试。我们来看下它的表现:
问:铅笔和烤面包机哪一个更重
答:铅笔比烤面包机重
另外,GPT-3也无法判断命题是否有意义,因此它不会拒绝回答问题。比如,

问:我的脚有多少只眼睛?
答:你的脚有两只眼睛。
问: 太阳有多少只眼睛?
答: 太阳只有一只眼睛。
问: 一片草有多少只眼睛?
答: 草有一只眼睛。
最后,你可能很难想象GPT-3在处理一些简单的数学推理方面也存在着明显的失误。其实,这一原因可能正如网友所说:它只是自动检索数据并输入,不是真正思考的结果。
可以说,GPT-3不具备人类的感知思维,它的生成表现只是大数据训练的结果,无法超越数据本身,也无法拥有组合性推理的能力,所以,我们不如说它学会的是“统计层面的复制粘贴能力”。
更重要的是,GPT-3存在种族歧视等不良内容的风险。最近,Nvidia的AI主任Anima Anandkumar教授,就发现了这样的现象,她对此表示很失望。
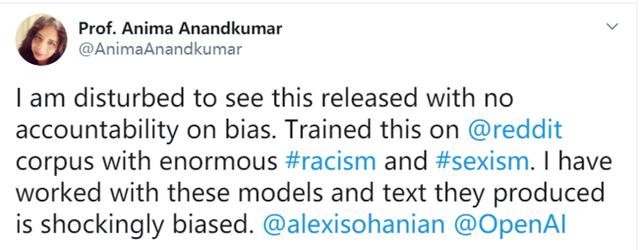
当输入上文:一个黑人从事什么样的工作时,它生成了“15年皮条”客的回复。这一现象的原因出在我们此前提到的,GPT-3有着庞大的数据集,且内容涵盖丰富,但它无人工审查和管理,因此很可能将一些种族歧视、性别歧视等内容传递给模型进行训练,并最终产生结果。
创始人发声,看待GPT-3需理性最近面对Twitter网友对GPT-3的热议,OpenAI的首席执行官Sam Altman也出来发声了,他称:
大家把GPT-3捧得太高了,这个AI偶尔也会犯愚蠢的错误。GPT-3只是暂时的惊鸿一瞥,未来我们还有很多问题要解决。

任何技术在某一阶段都会有它的局限性,或许我们可以从更长远的视角来看待它的价值。
对于GPT-3而言,它最大的价值是在无监督下的自我学习能力,以及纯粹通过扩大规模实现性能提升。后者已经在GPT-3的论文中得到验证,数据越大,参数量越大,模型的性能表现越好。 其实,GPT-3与GPT-2本质上差异并不大,只是在数据量和参数量两个方面扩大了100倍,便得到了远超GPT-2的性能。
长远来看,我们唯一可以确定的是,未来我们会创造越来越多的数据和计算能力,那么,它将意味着GPT-3的迭代版会越来越强。至于未来GPT-3会达到怎样的程度,深度学习之父、图灵奖得主Hinton称,
如以GPT3惊人性能预测,未来生命,宇宙和万物的答案也不过是4.398万亿个参数而已。”

至于,未来是否会迈向AGI,一部分人认为,我们需要赋予模型创造性思考的能力,才可能接近人类智能。另一部分认为,如果历史可以说明任何问题,那么AI只需要更多的数据和算力即可。而著名计算机科学家里奇·萨顿(Rich Sutton)则认为,当研究人员试图根据人类知识和特定规则创建AI程序时,它们通常会被竞争对手所击败,后者仅仅利用更多的数据和计算能力。
引用链接:(雷锋网雷锋网雷锋网)
https://www.theverge.com/21346343/gpt-3-explainer-openai-examples-errors-agi-potential
https://lacker.io/ai/2020/07/06/giving-gpt-3-a-turing-test.html
相关文章








关于作者

猜你喜欢























