作者 | 李峰
策划 | 凌敏
最早人工智能的模型是从 2012 年(AlexNet)问世,模型的深度和广度一直在逐级扩升,龙蜥社区理事单位浪潮信息于 2019 年也发布了大规模预训练模型——源 1.0。日前,浪潮信息 AI 算法研究员李峰带大家了解大模型发展现状和大模型基础知识,交流大模型在产业应用中起到的作用和 AI 服务新态势。本文整理自龙蜥大讲堂第 60 期,以下为本次分享原文。
大模型现状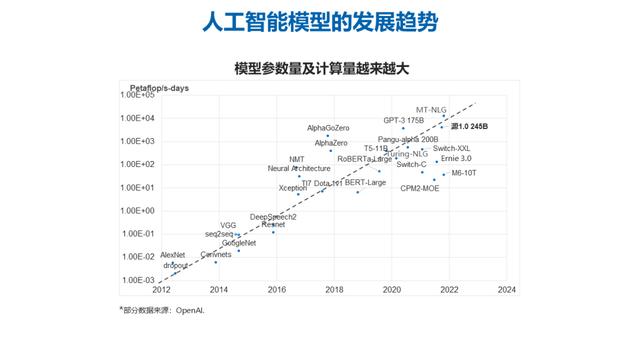
整体大模型的兴起绕不开一个基础模型结构 Transformer。Transformer 架构相当于是在接受输入之后,在内部进行了一个类似于查表的工作,其中的注意力层之所以叫注意力,最大的作用直白的来看就是可以去学习关系,所谓的注意力就是当我们看到一个东西的时候,对他感兴趣我们就会多看一会儿,对另外一个东西没有兴趣或者对它的兴趣比较低,则对它的关注会更少一点。这种注意力机制就是把所谓关注的程度转换成了一个可衡量的指标,这就是上面说到的注意力。
用这样的一个注意力层可以更好的去学习所有输入之间的一个关系,最后的一个前馈层又对输入的信息进行一个高效的存储和检索。这样的一个模型结构与之前基于 RNN 的模型结构相比不仅是极大地提升了自然语言处理任务的精度,而且在计算性能上也远超 RNN 类的模型。Transformer 结构的提出极大提升了计算效率和资源利用率。可以看到,在模型构建和训练算法的设计过程当中,算力和算法是相辅相成的,二者缺一不可,也就是我们提出的混合架构的一个算法设计。
另外 Transformer 结构之所以能够做大做强,再创辉煌,另一个根本的原因在于互联网上有相当多海量数据可以供模型进行自监督学习,这样才为我们庞大的水库中投入了庞大的数据资源和知识。
正是这些好处奠定了 Transformer 结构作为大模型基础架构的坚实的地位。

基于对前人的研究调研以及实证研究之后,我们发现随着数据量和参数量的增大,模型的精度仍旧可以进一步的提升,即损失函数值是可以进一步降低的。模型损失函数和模型的参数规模以及模型训练的数据量之间是呈现这样一个关系,现在仍旧处在相对中间的水平上,当模型和数据量的规模进一步增大的时候仍旧可以得到大模型边际效益带来的收益红利。

源大模型的结构上也做了一些创新,一方面是 2457 亿的参数,这个参数主要是基于 Transformer 的解码层结构进行了堆叠,也首次面向计算的效率和精度优化方面做了大模型的结构设计,针对 Attention 层和前馈层的模型空间结构也做了一些优化。我们改进的注意力机制来聚焦文章内部的联系,之后在整个计算过程当中我们也采用了张量并行、流水并行和数据并行三大并行方式来做模型的联合优化,从而提升模型训练的效率。
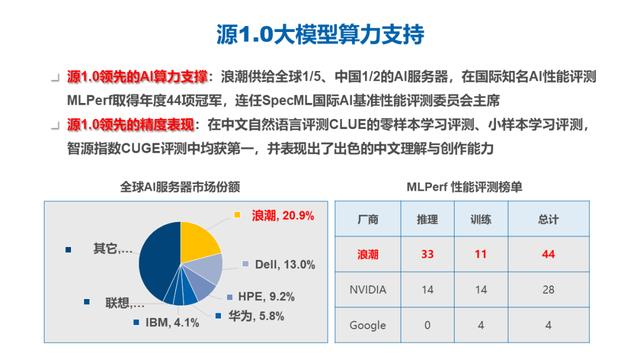
源大模型在整个训练阶段,因为模型结构和模型参数如此巨大,就需要更大规模的算力跟算力优化的能力支持。浪潮信息供给了全球五分之一,中国 50% 的 AI 服务器,并且在 MLPerf 等等这些与 AI 计算相关的比赛和精度优化、计算优化的比赛当中也是获得了非常多的冠军,也连任了 SpecML 的评委的主席,在这些过程当中我们积累下来的 AI 计算和性能优化方面的这些能力也在源 1.0 的训练过程当中被重复的赋能,所以我们的源 1.0 在训练过程当中,有非常强大的 AI 算力支持。
在大模型训练方面,我们采用了 2128 块 GPU,在单个 GPU 上的实际性能和理论性能的比值达到了 45%,远高于 GPT3 和 MT-NLG 等模型的训练过程。对于计算性能的提升会带来非常大的绿色环保的收益以及人力成本、时间成本上的收益。
源 1.0 在中文的自然语言测评的 CLUE 的零样本学习和小样本学习测评当中,获得了业界第一的水平,在智源指数 CUGE 上面的评测也获得了总分第一的成绩。模型除了可比较、可量化的评价标准以外也表现出非常丰富和出色的中文理解和创作能力,后文也有一些基于源 1.0 落地的应用实例,跟合作伙伴一起开发和赋能的相关案例,也会做一个简短的介绍。
我们在 WebQA 和 CMRC 的测评上面也横向比较了当时业界我们国内的一些模型的水平,可以看到在这两个任务上面我们也达到了一个业界高水平的成绩。
基于源 1.0 的技能模型构建大模型带来优异的精度表现和泛化能力,也带来一系列的问题。模型太大,部署起来会比较麻烦,因此我们基于源 1.0 在不同领域上面针对不同的任务构建了一些技能模型。

在实际应用当中,有 2000 多亿参数的大模型加载所需的显存空间就非常庞大。千亿参数模型需要用 8 张 GPU 卡做部署,推理时间要达到 6 秒多,而用百亿参数模型只需要 4 张 GPU 卡就可以实现 2 秒钟的推理效率,推理效率的提升还是比较明显的,这样的模型在实际的应用当中,尤其是对实时性要求较高的应用是非常占优的。
大模型的更新也比较困难,2000 多亿参数的模型,训练和微调的成本非常高,如果训练数据量少起不到对于这么庞大模型的所有参数更新的作用,如果训练数据规模大,虽然它的参数会被整体进行更新,但是会带来两个比较大的问题,一个是训练成本本身会变得很高,另外一个就是大规模的数据在训练过程当中有可能带来灾难性的遗忘,这会导致模型本身原有的泛化能力会有所衰减。还有就是应用困难,大模型的推理耗时相比传统服务高好多,推理的资源需求也会大很多。千亿参数的模型需要超过 600GB 的显存进行加载,推理时间超过 6 秒。因此我们希望采用知识迁移和模型压缩的方式来实现模型蒸馏。

为了构建技能模型我们对一些典型场景进行了数据收集,一种是古文,古诗文是中国传统文化的一个艺术结晶,因此我们希望能够通过现代的技术去挖掘古代的文学之美,所以我们去收集古文类的所有的数据和样本,然后去训练一个古文模型来去实现让大模型来做吟诗作对的这样一个能力。另一个是对话场景,我们对于自由对话场景收集了超过 2GB,覆盖多领域多话题的自由对话数据,以它为基础,我们后续要进行模型的蒸馏。
关于中英文翻译场景,我们收集了超过 145GB 的英文书籍和百科、新闻等国际官方文档,以及他们对应的中文翻译,期望在后续可以做翻译的模型。还有一个是问答场景。我们共收集了超过 3.9G 的公开知识,包括医疗、百科、金融等等多个领域。期望在后续可以去做问答的模型来匹配这样的一个知识问答场景。
无论是在做什么样的模型的时候,算法里面叫百算数为先,无论构建什么样的算法,我们都要从应用场景出手,在我们的模型开发实践过程当中都是以场景和场景所需要的数据着手,首先进行数据准备,之后才是相应的模型算法上面的一个开发工作。

我们秉承着构建开源社区,提升大家在大模型里面的应用能力,做了大模型的开源开放计划,构建了开源的一个官方网站(air.inspur.com),针对大学或科研机构的人工智能研究团队、浪潮信息的元脑生态伙伴,还有各种智能计算中心,以及对于中文自然语言理解和大模型感兴趣的各类开发人员和开发者进行免费开放,大家可以通过官网进行申请注册。开源开放的内容包括在官网上有模型的 API,以及高质量中文数据集和相应的处理代码开放出了 1T 的数据,这些只需在官网上进行申请就行。
另外,模型训练推理和应用的相关代码也在 github 上进行了开源,我们秉持一个开放的态度,鼓励并且面向 AI 芯片的合作伙伴与大家合作,做模型相关的迁移和开发工作。

还有一些比较典型的应用,这个是和我们的开发者,一起来做的一个 PoC 项目,面向数字社区的助理。开发者面向数字社区的工作人员,提供了一款数字助理,通过采用大模型来模拟到居委会进行投诉,或者是进行咨询的居民,然后来模拟他们的对话,并且对工作人员的回答做出一个判断,并且予以评分。通过这样的方式来提高工作人员面对突发情况的应对能力。

在另外一个场景里我们跟香港的浸会大学的教授一起基于大模型自然语言处理能力,开发一种心理辅导的培训机器人。这种也是基于这样的反向思维,让 AI 去承担心理咨询对话当中的求助者的角色,让咨询师根据心理来做求助的患者。
通过这样的方式,我们可以用大模型模拟可能存在问题的输入,通过标准工作者的工作内容去得到相应标准的答案。这其实也是互联网思维的一个非常典型的叫羊毛出在猪身上,我们通过这样的方式,也可以获取非常多标准的数据集和针对应用场景下的标准数据集,有这些数据的情况下,反过来之后,我们再对大模型做微调之后模型就有能力去扮演工作人员的角色,然后对心理咨询的患者直接进行辅导。这样的过程其实就是在 ChatGPT 当中提到的 RLHF 的人环强化学习的一种合理的运用。
本文转载来源:
相关文章









关于作者

猜你喜欢























