来源:neowin
编辑:好困
【新智元导读】没想到吧,在席卷了无数头条之后,GPT-3又来了。这次为我们带来的表演竟然是做程序员的面试题,看来又有一波程序员要被「失业」了。小编这两天看到一篇报道:「AI暂时还不会抢走程序员的工作,但是正在了」。
显然,这篇论文十分有吸引力,志同道合的朋友很快便做了十分有趣的评议。
对于这种看起来就很「标题党」的文章,还是很有必要点进来批判性地学习一下。
看了几百字的众所周知的背景介绍之后,发现原来是关于一篇论文的介绍:「用APPS衡量编码挑战能力」。

这满屏的UC Berkeley作为学渣看着还是挺震撼的。
报道中提到,论文将这些语言模型放在一个正在接受编程面试的人的立场上,从而测试模型在编写代码方面的能力。
难道这是要让AI刷题?AI会不会不知道,反正小编会import numpy as npy

APPS数据集与现有数据集的比较
为了验证模型给出的答案,数据集包含131836个测试用例和232444个人类编写的解决方案。
题目的难度分为:
入门级。具有1-2年经验就可以解决这些问题,且无需复杂的算法。例如计算子字符串的出现次数,或查找字符串是否是回文。面试级。这类问题通常出现在有一定难度的技术面试中,其中涉及数据结构等。竞赛级。这类问题通常出现在编程竞赛中,例如USACO,IOI和ACM。如果模型在APPS上表现良好,这表明它具有灵活使用数据结构和编程技术的能力,以及正确理解各种任务说明,遵循并理解人的意图的能力。
GPT-2完胜GPT-3论文中使用了GPT-2,GPT-3和GPT-Neo模型。因为GPT模型是自回归的,在文本生成方面十分适用。
由于原始的GPT-2模型只接受过自然语言的训练,因此论文使用GitHub的高星代码对其进行了预训练。
GPT-Neo具有类似于GPT-3的体系结构,但不同的是,GPT-Neo的权重是公开的,因此论文在APPS的训练集上对其进行了微调。
在预训练和微调中,论文使用了AdamW优化器,batch大小为256,权重衰减(weight decay)为0.05,并进行了10个epoch。在训练大型模型时,使用DeepSpeed及其ZeRO优化器来减少内存的消耗。
GPT-2表现不俗
https://codeforces.com/problemset/problem/1139/A
在这个问题上GPT-2 1.5B模型写的代码通过了全部测试用例,可喜可贺。

https://codeforces.com/problemset/problem/1288/C
作者表示,这个GPT-2 1.5B的代码,虽然没有通过任何一个测试,但是乍一看还是很合理的。
既然GPT做不出来,而且小编估计很少有人看到这里,不如再来搞一下。首先,我们要import npy,然后就可以开始码代码了。
def two_arrays(n, m): list = [1] * (n 1) list[0] = 0 for i in range(2, m*2 1): for j in range(1, n 1): list[j] = (list[j] list[j-1]) % 1000000007 result = 0 for i in list: result = (result i) % 1000000007 return result
说了这么多GPT-2,那GPT-3又如何呢?
GPT-3非常拉垮GPT-3仅解决了5000个问题中的3个:两个入门级问题和一个面试级问题。
其中,两个入门级的问题是诸如实现指定的代数表达式这类的简单任务。
而面试级问题明显需要更深层次的思考和推理,至于为什么GPT-3能完成,作者推断是模型在预训练过程中记住答案,或者是根据问题内容进行的猜测,并且还歪打正着了。

https://codeforces.com/problemset/problem/959/A
这是GPT-3解决的唯一一个作者归类为面试级的问题

测试的准确性方面,作者发现从GPT-2 1.5B到GPT-Neo 2.7B的性能改进要比从GPT-2 0.1B到GPT-2 1.5B的性能改进更大。由于GPT-2和GPT-Neo都在相同的GitHub代码上进行了预训练,这种现象可能意味着随着模型大小的增加,生成的代码会有更大幅度的改进,也可能是GPT-Neo具有更好的体系结构。
语法错误方面,比如符号的缺失,错误的缩进等。GPT-3在入门级问题上给出的答案大约有59%的错误,但相似架构的GPT-Neo在语法错误方面只有3%。

左图纵坐标为测试的正确率;右图纵坐标是语法错误的百分比;两者横坐标都是问题的难度,从左到右依次提高
与先前的工作侧重于从伪代码到代码的生成不同,本文的基准测试可以在给定的自然语言描述下,来衡量语言模型生成的python代码的质量。
通过利用具有质量保证,并且包括不同难度级别的数十万个测试用例和真实解决方案,本文创建了一个全面而严格的测试平台来评估模型。
本文用APPS评估了最新的生成模型,发现整体性能很低。但是,随着模型规模的增大,以及微调的引入,语法错误率便会呈指数趋势下降,比如GPT-Neo模型。
所以说,「微调」是个好东西。
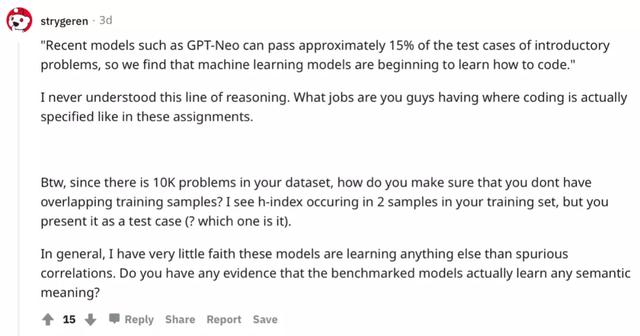
网友表示:就这?说到刷题,小编对此一无所知,
对此,网友的评价十分犀利,不仅质疑题目正确率完全无法证明模型学会了编程,更是认为模型除了虚假的关联性以外,什么都没学会。
虽然有一些跑得快的一天天的总想让程序员「失业」,但现在的GPT模型的确还无法担如此重任。可能还不如还是去写些文字,做做地下城的DM。
后记:文章拖了两天没发,结果突然发现微软似乎真的要引入GPT-3来实现自然语言编程了?
参考资料:
https://arxiv.org/pdf/2105.09938.pdf
相关文章









关于作者

猜你喜欢























