机器之心报道
机器之心编辑部
时隔一年,OpenAI 放出的预训练语言模型 GPT-3 再次让人刮目相看。

根据 OpenAI 的统计,人类对 GPT-3 175B 模型生成的约 500 词文章的判断准确率为 52%,不过相比于 GPT-3 control 模型(没有语境和不断增加的输出随机性且只具备 1.6 亿参数的模型),GPT-3 175B 生成的文本质量要高得多。果然很暴力啊!


GPT-3 在多个语言建模任务中的表现
GPT-2 发布时在多个领域特定的语言建模任务上实现了当前最佳性能。现在,我们来看参数和成本大量增加后的 GPT-3 效果如何。
OpenAI 在多项任务中对 GPT-3 的性能进行了测试,包括语言建模、补全、问答、翻译、常识推理、SuperGLUE 等任务。具体结果如下表所示:
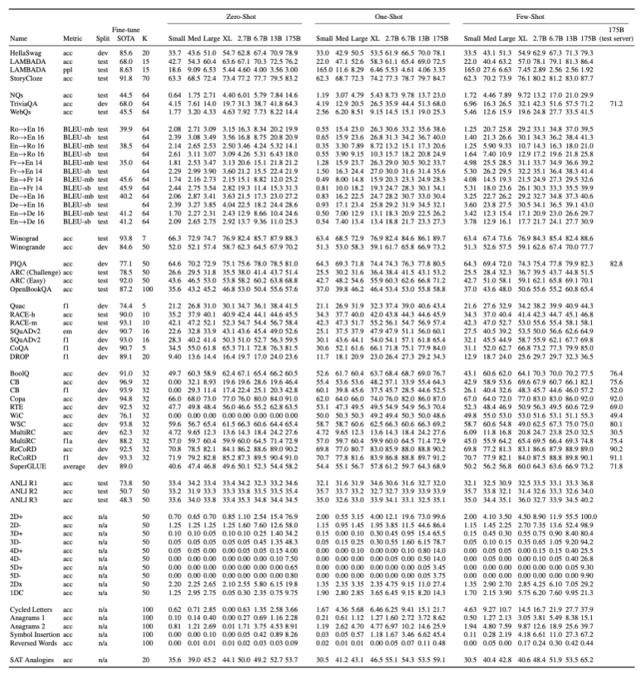
不同模型在所有任务上的性能,以及任务的 SOTA 性能(包括模型规模、训练细节等信息)。
GPT-3 技术解析
近期大量研究工作表明,通过对大量文本进行预训练,并且针对特定任务进行微调,模型的性能可以在许多 NLP 任务以及基准测试中获得显著提升。
最近,OpenAI 团队训练了 GPT-3(这是一个具有 1750 亿参数的自回归语言模型,参数量是之前任何非稀疏语言模型的 10 倍),并在少样本(few-shot)环境下对其性能进行了测试。在所有任务中,GPT-3 无需进行任何额外的梯度更新或微调,完全只通过模型与文本的交互,即可直接应用于特定任务与少样本 demo。
GPT-3 在许多 NLP 数据集上均有出色的性能,包括翻译、问答和内容填充任务,以及多项需要实时推理或域适应的任务,如利用新单词造句或执行三位数运算等。GPT-3 生成的新闻文章足以以假乱真,令人类评估员难以分辨。
不过,GPT-3 也有缺点。该研究团队发现 GPT-3 (few-shot) 在文本合成和多个 NLP 数据集上的性能不够好,还存在一些结构和算法上的缺陷。另一个语言模型大多会有的缺陷「预训练样本效率较低」的问题它也有,GPT-3 在预训练期间阅读的文本比人一生读的还要多。此外,还有可解释性问题等。
预训练方法
OpenAI 团队使用的基础预训练方法包括模型、数据与训练三部分。GPT-3 的训练过程与 GPT-2 类似,但对模型大小、数据集大小与多样性、训练长度都进行了相对直接的扩充。关于语境学习,GPT-3 同样使用了与 GPT-2 类似的方法,不过 GPT-3 研究团队系统地探索了不同的语境学习设定。
OpenAI 团队明确地定义了用于评估 GPT-3 的不同设定,包括 zero-shot、one-shot 和 few-shot。
Fine-Tuning (FT):微调是近几年来最为常用的方法,涉及在期望任务的特定数据集上更新经过预训练模型的权重;
Few-Shot (FS):在该研究中指与 GPT-2 类似的,在推理阶段为模型提供少量任务演示,但不允许更新网络权重的情形;
One-Shot (1S):单样本与小样本类似,不同的是除了对任务的自然语言描述外,仅允许提供一个任务演示;
Zero-Shot (0S):零次样本除了不允许有任何演示外与单样本类似,仅为模型提供用于描述任务的自然语言指示。
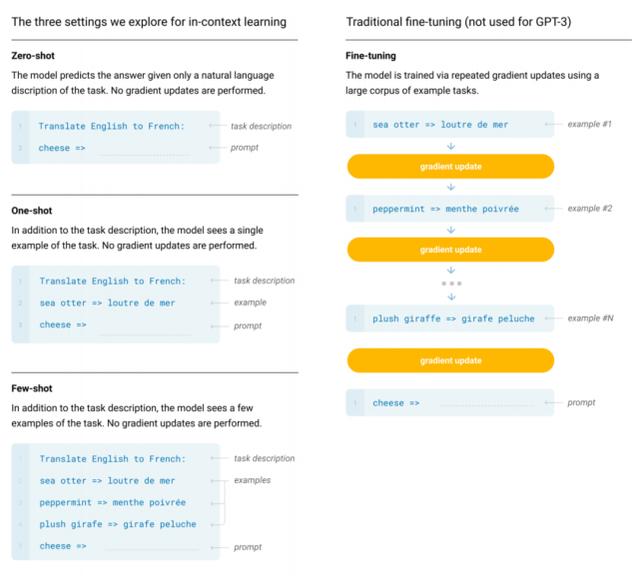
表 2.1:该研究所训练 8 个模型的大小、架构和超参数信息。所有模型一共使用了 3000 亿 token。
为了最大程度地减少节点之间的数据传输,该研究从深度和宽度两个方向进行跨 GPU 模型分割。然后基于跨 GPU 模型布局的计算效率和负载平衡选择每个模型精确的架构参数。先前的研究 [KMH 20] 表明,在合理范围内,验证损失对这些参数并不是特别敏感。
训练数据集
下表介绍了 GPT-3 训练过程中所用的数据集。

表 2.2:用于训练 GPT-3 的数据集。
OpenAI:其实我们也有点玩不起了
最开始是训练不动,后来 finetune 不起,现在到了 GPT-3 模型的时代,我们连 forward 也要不起了。
你肯定想问这样一个问题:训练 GPT-3 模型需要花多少钱?我们目前还只能粗略地估计——训练一个 BERT 模型租用云算力要花大概 6912 美元,训练 GPT-2 每小时要花费 256 美元,但 OpenAI 一直没有透露一共要花多少小时。
相比之下,GPT-3 需要的算力(flops)是 BERT 的 1900 多倍,所以这个数字应该是千万美元级别的,以至于研究者在论文第九页说:我们发现了一个 bug,但没钱再去重新训练模型,所以先就这么算了吧。

但即使这样它的效果依然惊人。

GPT-3 的实验结果,似乎验证了 Richard Sutton 去年颇具争议的论断,他在《苦涩的教训》的最后写道:「我们应该从苦涩的教训中学到一点:通用方法非常强大,这类方法会随着算力的增加而继续扩展,搜索和学习似乎正是这样的方法。」
关于 GPT-3 的更多详情,参见论文:https://arxiv.org/abs/2005.14165
相关文章









关于作者

猜你喜欢























