
就连笔者这种在IT界摸爬滚打十几年的老程序员,在试用debuild网站后,吃惊得说不出话来。不过可能是突然压力增大,目前该网站已关闭新增注册的功能。

虽然NLP好像不是Open AI最为关注的领域,不过他们在自然语言处理方面成果一直引人关注。在去年底《权利的游戏》全面烂尾后,有人使用模型GPT-2 来重写剧本的结局。网友普遍反应AI改写的新结局比电视剧的版本要好。


自然语言处理发展历程
机器学习的本质是通过找到结果与多维输入之间的关系来进行预测,计算机是没有办法处理语言的,所以需要将自然语言转换为向量才能进行机器学习。
在本轮AI行业全面爆发之初,行业还并未找到将单词转为向量的好办法,所以自然语言处理方面的程序一直比较慢,直到Word to Vector出现。
word2vec出世:在这项技术发明之前,自然语言处理方面的应用基本是依靠专家制订语法规则,交由计算机实现的方式来推进。
word2vec的核心理念是一个单词是通过其周围的单词来定义,word2vec算法通过负例采样暨观察一个单词不会和哪些单词一起出现;跳字处理暨观察一个单词周围的单词都有哪些,来完成单词到向量的转化过程。将单词转化为向量也被称为词嵌入的过程,从而让自然语言处理变成一个能让计算机自动执行的过程。
一个好的词嵌入模型要满足两个条件一是词义相近的单词在空间上的距离要近,比如七彩虹、铭宣、影驰等显卡品牌对应的向量应该在词空间中的距离比较相近。二是有对应关系相同的单词对应向量的减法结果相等,比如v(中国)-v(北京)=v(英国)-v(伦敦)。
word2vec加速自然语言处理的发展速度,GPT、BERT、XLNET等模型相继被提出,虽然他们的流派有自编码和自回归的不同,但是对传承词嵌入思想的继承还是比较一致的,这些模型都是在不借助语法专家的知识库的情况下,直接利用词与词之间的关系来进行模型训练。
自回归模型:GPT系列都是典型的自回归架构的自然语言处理模型。通俗地讲,自回归使用自身做回归变量的过程,一般说来记为以下形式:

GPT-3的应对之道
GPT-3的作者在论文开头就指出,通过对大量文本进行预训练,针对特定任务进行微调,模型的性能可以在许多 NLP 任务以及基准测试中获得显著提升。
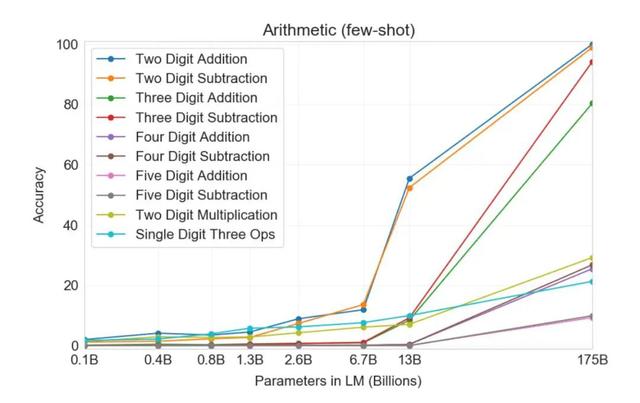
如图所示,X轴代码模型的参数数量级而纵轴代表准确率,模型规模越大,准确率也会随之升高,尤其是在参数规模达到13亿以后,准确率提升的速度还会更快。简单讲,GPT-3的决胜之道在于其模型的训练集特别大,参数茫茫多。

相关文章









关于作者

猜你喜欢























