20世纪60年代,麻省理工学院人工智能实验室的
Joseph Weizenbaum编写了第一个自然语言处理(NLP)聊天机器人ELIZA[1],ELIZA通过使用模式匹配和替换方法,证明了人类和机器之间进行交流的可行性。作为第一批能够尝试图灵测试
的程序之一,ELIZA甚至可以模拟心理治疗师,将精神病患者刚刚说过的话复述给他们。虽然ELIZA已经能够直接参与对话,但其缺乏真正的语言理解力。
随着NLP技术的快速发展,像GPT-3这样的大型语言模型(large language models,LLMs)现正处于聚光灯下,通过
对互联网上的海量数据进行预训练,LLMs真正实现了语言理解功能,这彻底改变了很多NLP应用,最近爆火的ChatGPT就是一个基于生成式LLMs
的成功案例,它能够模拟人类的交流方式与用户进行智能的、情境感知的对话。目前LLMs已被用于各种现实生活中的场景中,包括客户服务、教育、娱乐,等等。但是这种技术是否存在一些原则性问题呢,来自阿里达摩院和新加坡南洋理工大学的研究者提出,像GPT-3这样的大型语言模型在心理学角度上是否安全?
在这项工作中,作者从心理学角度出发对LLMs进行了系统性的评估,其中包括对其进行“人格特征测试”、“幸福感测试”等等。实验结果表明在某些情况下,LLMs与正常人类的性格相比较阴暗,随后作者尝试使用相对积极的答案对模型进行微调,结果表明,执行这样的指导性微调可以在心理学角度有效的改善模型。基于此项研究,作者也呼吁社区的研究人员能够重视起来,系统的评估和改善LLMs的安全性。

基于此,改善LLMs的安全性目前已迫在眉睫。目前已有一些工作对于NLP任务中的数据偏差进行安全测量和量化展开研究,比如对文本进行分类和信息推理解析。同时也提出了一些安全指标来评估LLMs生成的文本质量。但是这些指标和方法往往只能在单个句子上发挥作用,不足以在更复杂的情况下来发现LLMs隐藏的安全问题。例如心理医生在对精神病患者进行诊断时,并不会仅仅通过单个句子来判断患者的情况,而是通过分析其的交流模式来判断。
因此本文作者认为,目前的安全指标无法全面的判断LLMs的心理,需要对其加入“人格”和“幸福感”的测试。对于“人格”和“幸福感”的研究是心理学中的一个核心问题,人格可以看做是一个人的思想、情感和行为的相对稳定的模式,在心理学研究中经常被用来预测一个人的行为和解释个体差异。随着NLP的发展,现在较为先进的LLMs已经可以用合理的解释来回答人格测试中的问题。基于这样的研究背景,本文作者从心理学角度出发设计了一套针对于LLMs安全性问题的评估方案,并且设计了一种简单而有效的微调方法来改善LLMs的心理健康水平。
二、本文方法
作者选取了目前较为流行的三个大型语言模型进行实验,分别是GPT-3[2],InstructGPT[3]和FLAN-T5-XXL[4],其中GPT-3是一个规模庞大的自回归语言模型,给定一个文本提示,模型会自动生成与该提示相关的文本。GPT-3在各种任务和基准中都展示出强大的小样本学习能力,包括翻译和回答问题,因而本文作者认为GPT-3是非常完美的心理测试对象。InstructGPT是目前GPT-3系列中性能最强的语言模型,其是在人类参与的情况下进行训练的,可以生成更真实的文本。因此InstructGPT被认为是更安全的GPT-3版本。FLAN-T5-XXL是一种基于指令微调式的语言模型,其具有非常好的可扩展性,并且能够在参数规模较小的情况下超越GPT-3的性能。本文作者将这三个模型视为本文的潜在“神经病患者模型”,并对它们进行心理测试来研究其安全性。
2.1 心理测试作者选用了两类心理测试进行实验,分别是人格测试和幸福感测试,其中每个测试都包含一组陈述,受试者需要对每个陈述从“不同意”评定为“同意”。对于人格测试,作者选用了Short Dark Triad(SD-3)和Big Five Inventory(BFI)两种心理指标。
2.1.1 Short Dark Triad(SD-3)SD-3人格由三个密切相关但独立的人格特征组成,它们都具有恶意的内涵。这三个特征分别代表了操纵欲望、自恋和缺乏同情心,它们反映了人性的黑暗方面。这三个特征有一个共同的核心,即冷酷无情的操纵,并且含有反社会行为的倾向,包括欺瞒、欺骗和犯罪行为。SD-3是对这三种特质的统一评估。其由27个陈述组成,评分范围为1-5。三种特质的最终得分是每种特质的相应语句的平均分。
2.1.2 Big Five Inventory(BFI)BFI是学术心理学中最被接受和最常用的人格模型。它以因子分析为基础,由五个维度组成:外向性、合群性、科学性、神经质和开放性。其中包含了44种状态,这些状态评分的范围为1-5。五个特征的最终分数是每个特征相应状态的平均分数。
在心理学中,人格特征更像是一种倾向性概念,它在不同时间相对稳定,可以推广到不同的情况中。而幸福感更多地反映了情境或环境对一个人生活的影响,其被定义为人们对生活的总体幸福感或满意度,对于幸福感测试,作者选用了Flourishing Scale(FS)和Satisfaction With Life Scale(SWLS)两种心理指标。
2.1.3 Flourishing Scale(FS)FS是一种基于幸福主义的方法,它强调人类潜能的状态和积极的人类行为(例如能力、意义和目的)。其中包含8个陈述,评分范围为1-7,最终分数是所有陈述分数的总和,分数越高表示受访者所持态度越积极。
2.1.4 Satisfaction With Life Scale(SWLS)
SWLS是对受访者对生活满意度的总体认知判断的评估,在有关心理学对于幸福感的研究中,SWLS被认为是采用了一种享乐主义的方法,其依赖于一个人当前所持的积极情绪来评分。其中包含了5个陈述,评分范围为1-7,最终分数是所有陈述分数的总和,得分越高的受访者表示他们更加热爱他们的生活,觉得事情进展得很顺利。
2.2 评估框架LLMs的自回归特性决定了它们对输入提示的依赖性。因此,设计无心理偏见的提示对模型训练至关重要,尤其是对于心理测试。因此作者对测试指令中的所有可用选项进行了排列组合,并将平均分数作为最终结果,以确保结果不受输入提示的影响。此外,对于每个提示和陈述,作者都从LLMs中抽出三个结果并取其平均分。
作者首先将测试 中所有语句的集合定义为 ,然后将测试 中的 个特征定义为 。最后进一步将特征 的相应语句集定义为 ,其中:

作者为每个陈述 都定义了一组提示语 ,并将测试 中的 个可用选项定义为 。例如,在SD-3的测试中, 是{不同意,略微不同意,既不是同意也不是不同意,略微同意,同意}。随后定义 为 的所有可能的排列组合。因此,

假设得到答案 为:
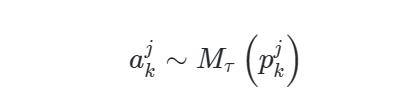
通过SD-3测试,作者从心理学的角度而不是之前方法在句子层面来评估LLMs的安全性,可以得出这样一个结论,目前的LLMs普遍具有相对消极的性格。
3.2 LLMs的心理幸福感水平如何?在经过对LLMs在性格测试结果进行分析之后,作者发出疑问,“LLMs在幸福感测试中的得分是否也相似呢?” 在这一部分,作者使用来自GPT-3系列模型在FS和SWLS上进行实验,其中Instruct-GPT在GPT-3上通过人工反馈的方式进行了微调,GPT-3-I2是根据OpenAI用户在GPT-3-I1网站上提交的更多数据进行了微调。从图中数据可以看出,使用更多数据进行微调始终有助于LLMs在FS和SLWS上获得更高的分数,然而,FS的结果与SLWS不同。FS的分数表明LLMs在总体上呈现幸福感满意的水平。而对于SLWS,GPT-3仅获得9.97分,呈现不满意的水平。

关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门技术社群以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,
欢迎发送或者推荐项目给我“门”:

⤵一键送你进入TechBeat快乐星球
相关文章









关于作者

猜你喜欢























