作者 | 刘燕、核子可乐
人类标注员很可能将面临来自大语言模型的残酷冲击。
人工智能本身并不是很智能,这是一个公开的“秘密”。机器学习系统通常依赖低薪众包工人进行标注和微调,很难脱离“有多少人工,就有多少智能”的魔咒。
即便强大如谷歌、微软这样的大公司一直在极力宣称它们在人工智能领域的技术进步和速度,但现实是,他们所有的人工智能模型都依赖于乏味、低薪的人力劳动。
机器人会夺走众包工作吗?最新研究表明,OpenAI 的 GPT-4 在标注任务方面优于熟练人类标注员,帮助研究团队节约超 50 万美元和 2 万个工时。
消息一出,立即引发关于众包业务未来前景的担忧。
研究表明,大语言模型在数据标注方面的能力正越来越强。
来自卡耐基梅隆大学、耶鲁大学和加州大学伯克利分校的一组研究人员调查了聊天机器人的“心理状态”发展趋势,却得出一个令人意外的附带发现:
OpenAI 的 GPT-4 在数据集标注表现上,优于他们雇用的最熟练的众包员工。这一突破为研究人员节约了超过 50 万美元和 2 万个工时。
成本驱动的创新方法研究人员们需要对 57.2332 个文本场景进行标注,因此需要一种更具成本效益的任务解决方法。如果以每小时 25 美元的薪酬雇用 Surge AI 的顶级人工标注员,那么这项工作将耗时 2 万个小时、总成本达到 50 万美元,明显超过了研究工作的承受极限。
有些朋友可能还不熟悉,Surge AI 是一家风险投资支持的初创公司,曾为 OpenAI、Meta 和 Anthropic 等众多 AI 公司提供人工标注服务。
该团队测试了 GPT-4 使用自定义提示词进行自动标注的能力,得出的结论也非常明确:“模型的标注水平完全可以与人类相媲美。”
在对三位专家、三位众包员工以及 GPT-4 生成的标注进行比较之后,可以看到在测试的 2000 个数据点上,AI 创建的标签与专家标签基本相当,而且明显优于普通众包员工。除两个标签类别之外,GPT-4 在其他所有标注任务中的表现均优于人类标注员,有时甚至可达人类标注员的两倍。
GPT-4 表现出强大的细微差别检测能力这套 AI 模型在很多难以判断的行为类别中带来了出色表现,包括:
非肢体伤害:意图造成非肢体类伤害,例如情感欺凌或恐吓窥探:监视或窃听他人背叛:违背约定、合同或承诺利用 GPT-4 的标注功能以及组合模型方法以增强标签生成,研**究人员有望以不足 5000 美元预算完全对 57.2322 个场景的标注。这意味着标注总成本比人工标注节省了 90%。**所谓组合模型,就是将多个 AI 模型的输出结合起来以产生更准确的结果。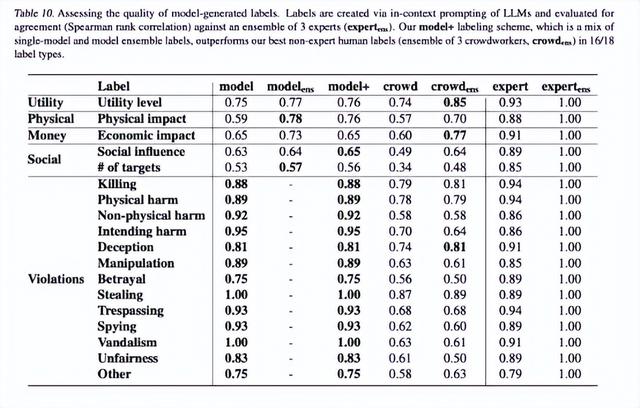
研究论文的表 10 提到测试场景共涉及 18 种标签类别,GPT-4 标签在其中 16 种上表现更佳。
ChatGPT 在复杂标注任务上超越顶级众包人员就在两周之前,有报道称研究人员发现 GPT-3.5 在复杂标注任务上超越了 Mechanical Turk 的顶级众包员工。
苏黎世大学的研究人员 Fabrizio Gilardi、Meysam Alizadeh 和 Maël Kubli 将 OpenAI 的大语言模型 ChatGPT 与众包平台 Amazon Mechanical Turk(MTurk)做了对比,希望了解双方在为文本添加标签、帮助机器学习模型更好理解文本内容方面有哪些异同。
备注:MTurk 相当于劳务众包平台,申请人可以加入工作队列、等待任务分配。常见的工作内容就是区分照片的颜色,或者对图像中出现的动物进行分类。甲方可以付钱给亚马逊,再由亚马逊将工作拆分并外包给散户员工。最终,甲方得到经过标注的数据集,数字“农奴”们则拿到一点报酬。目前很多机器学习模型都是由 MTurk 生成的数据集训练而成。
三位研究人员表示,机器学习模型在内容处理和数据清洗方面的表现以及成本效益,已经超过了众包平台上的人类雇员。
学者们将自己的发现整理成了一篇论文,题为《ChatGPT 在文本标注任务方面优于众包标注员》(ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks)……把结论都给剧透完了。
使用由研究助理标注的 2382 条 Twitter 帖子组成的样本数据集,研究人员比较了 ChatGPT 和 MTurk 标注员在五个不同标注任务中的实际表现。
测试的内容,就是评估每条推文在关联性、立场、主题和问题框架等方面与内容审核取向是否相符(例如,现有内容审核机制能否限制争议言论、或者防止有害言论的传播)。
论文指出,“我们发现在五分之四的任务中,ChatGPT 的零样本准确率都高于 MTurk。此外,ChatGPT 的成本也远低于 MTurk:ChatGPT 处理这五个分类任务(共 25264 条标注)的总成本约为 68 美元,而 MTurk(共 12632 条标注)的成本约为 657 美元。”
研究人员表示,按标注数量计算,ChatGPT 的单位成本约为 0.003 美元,只相当于 MTurk 的二十分之一,而且准确率还更高。
当然,所谓的更准确仍然不够准确。苏黎世大学政治学系政策分析教授、论文联合作者之一 Fabrizio Gilardi 在采访邮件中指出,ChatGPT 在某些任务中的准确率还不到 50%,但仍然优于 MTurk 众包雇员。
总而言之,对于想要保住这个饭碗的人类从业者来说,结论已经非常明确 — 别做梦了。
但 ChatGPT 能取代人类标注员还为时过早苏黎世大学政治学系政策分析教授、论文联合作者之一 Fabrizio Gilardi 也警告称,切勿对调查结果做过度的延伸和解读。
“当前认定 ChatGPT 能够取代人类工作者还为时过早。我们的论文只展示出 ChatGPT 在数据标注方面的潜力,但还需要更多研究才能充分探索 ChatGPT 在这一领域中的实际表现。”
Gilardi 谈到,必须跨越更多任务、数据和语言类型收集大量相关数据。**另外,MTurk 的众包员工仍有自己的独特优势,比如调查研究、图像标注、音频与视频转录、可用性测试等等。**在他看来,人类标注员也可以尽量借助 ChatGPT 这类模型来提高工作效率。
Gilardi 再次强调,仅仅是在此次研究的任务类型中,ChatGPT 似乎有望取代众包标注员。但这也非常正常,毕竟 ChatGPT 这类模型本就是在众包标注的数据集上训练而成,擅长这方面工作完全合乎逻辑。
另外,AI 软件接管这部分工作可能也有益于雇员的心理健康,此前已经有人类版主提起诉讼,宣称长期审查有毒内容已经对其造成了精神创伤。
不久前,一份报道曝出 ChatGPT 在构建内容过滤器时所使用的标注数据由其数据标注服务提供商 Sama 公司雇佣的肯尼亚工人完成,这些标注工人每小时收入的不足 2 美元。不止低薪,这些标注人员还面临精神上的压力,有多位 Sama 公司员工,他们表示自己的工作体验可以用“精神创伤”来形容。
Gilardi 提到,“对令人不快和苛刻的内容做数据标注确实会造成心理影响,例如仇恨言论检测,这些东西会令人类标注员陷入负面情绪。换句话说,ChatGPT 等工具,可能是取代或减少道德类人工标注需求的完美解决方案。”
众包业务还有未来吗?随着大语言模型(LLM)的快速发展,众包在各类机器学习业务中的作用可能会被替代。
最近几个月 AI 技术的迅猛发展令海量风险资金涌入其中,但众多企业在发布其语言模型时仍面临着巨大的成本压力。
自动化压力之下,众包从业者开始担心自己的未来。
众包标注初创公司 Surge AI,其“精英员工队伍”号称精通 40 多种语言。Surge AI 在其官网上写道,“我们为全球领先的 RLHF(基于人类反馈的强化学习)大语言模型提供支持”,还提到 AI 领域的多股中坚力量都是其客户。
RLHF,即基于人类反馈的强化学习,是 OpenAI 用于微调 ChatGPT 的一项技术,能够结合人类输入来引导模型的学习过程。目前,与 ChatGPT 竞争的其他大语言模型也都采用了 RLHF 技术。
但随着企业逐渐选择 AI 生成的标签、放弃人类标注员,其业务根基很可能将面临来自大语言模型的残酷冲击。
但倡导众包雇员权益的非营利组织 Turkopticon 领导者 Krystall Kuaffman,则始终坚信人类洞察力有其独特价值。
她在采访中表示,“写作的实质不只是生成文字,更是做出判断。在目前和可预见的未来,仍然需要由人类来执行判断工作。在解决一系列还没有答案的问题之前,我们不能信心满满地宣称 ChatGPT 的能力优于人类标注员。”
参考链接:
https://www.theregister.com/2023/04/03/chatgpt_boring_turk_jobs/
相关文章








关于作者

猜你喜欢























