“chatGPT”到底是什么啊?
chatGPT是一个智能对话应用,也称聊天机器人,可以回答用户的各种天南海北的问题。
chatGPT背后的技术被称为“大型语言模型”(Large Language Model,简称LLM),是人工智能技术中,属于深度神经网络的技术。

从原理上来说,我觉得chatGPT像是一个知识的压缩器:它把很多知识浓缩在里面,然后你可以通过对话问答的方法把知识取出来。如果把浓缩知识的过程称为“压缩”,那取出知识的过程就是“解压缩”。从这个意义上讲,chatGPT是一个知识的“压缩-解压缩器”。
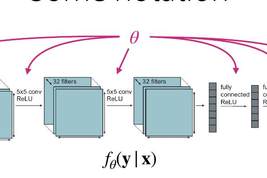
本来知识的表现形式,是我们看得懂的文本,经过机器的重新编排,存储在一个称为“神经网络”的东西里,也就是今天我们所说的 “模型”。人的大脑有一张“神经网络”,是由很多相互连接的神经元构成。
机器学习技术参照了这个名字,也叫“神经网络”,实际就是许许多多彼此连接的数据节点,其中,大型语言模型拥有的数据节点少则几百亿个、多则上万亿个。
知识被重新编排后,就用这些数据节点的参数以及节点之间的关系来表示,不再是一篇篇可读的文本。“解压缩”就是把知识从网络中恢复出来,变成我们可读的文本。而“解压缩”的钥匙,就是我们问chatGPT的问题。

问题:能不能再解释得详细一点?为什么chatGPT能回答问题?
回答:
我用“搜索引擎”来做对比,有利于说清楚问题。
网上的知识非常多,以网页或数据库的形式存在。搜索引擎首先要去抓取网页,上千亿的网页,就是获取知识的过程,这是搜索的第一个功能。
然后,搜索引擎要浓缩这些网页,它会把文章拆成一个一个的词,以词为单位来重新组织文章,就是制作“倒排表”,“倒排表”就是每个词后面跟着一串它出现过的文档编号,这样查询时可以快速找到哪些文章包含了查询词。这是搜索引擎的第二个功能“索引”。
再然后,当用户来查询的时候,输入一个或几个词,包含这些词的文章是相当多的,那就要给文章排序,尽量让用户想要的结果排在前面。这就是搜索引擎的第三个功能“排序”。
搜索引擎就有这样三个主要功能:获取知识——抓取;编排知识——索引;把你想要的排前面——排序。还有其他很多细节,大致是这样。
可以说,搜索引擎也是一个知识的“压缩-解压缩器”。类似的,我们也可以按照“获取知识-编排知识-呈现知识”这样三个方面来理解chatGPT。
在“获取知识”方面,chatGPT有三个阶段。在第一阶段,研发团队收集大量的网页或者数据库,用里面的文本信息作为训练模型的“语料”,这个量很大,按单词个数来算能达到上万亿。在第二阶段,模型优化阶段,会有专门设计的一些问答数据,这个数量很少,但对模型效果很关键。第三阶段,当模型的效果足够好、可以对用户开放之后,chatGPT可以通过和用户的对话来获取数据,研发团队还开发了插件,方便合作方将各种数据库接入chatGPT,来丰富其指定场景下的知识,这个数据量可以是海量的。
在“编排知识”方面,chatGPT和搜索引擎不同,它把知识揉得更碎,文本变成了数字编码、以节点参数和节点之间的关系的形式来存储,知识就好像“融化”在网络里;当用户来问时,chatGPT会用同样的方式把用户的问话也变成数字编码,输入神经网络,这样就触发了神经网络中的相关信息,回收信息后,再经过一个和揉碎相反的过程——就是解码,就形成了返回的文案。
在“呈现知识”方面,用户用日常对话来获取知识,而不是使用搜索引擎时的查询词。返回的结果也不同,搜索引擎会返回一组网页,而chatGPT给的是通顺的文案。chatGPT还能对信息做梳理,总结成结构化的文案,这是让人印象深刻的地方。至于答案中信息的相关性和重要性等,可能已经被考虑在神经网络的参数里,具体机制我不懂。
另外的区别是,chatGPT还可以和你做多轮问答,有根据上下文调整答案的能力。这取决于它能编码的长度,就是能把多长的问题放到网络中去。
当然,你用日常问话去问搜索引擎也行,但是返回的结果往往很不好,为了改善搜索结果,搜索会在下拉框里补充一些提示词。这当然和千变万化的日常对话没法比。
总而言之,作为知识的“压缩-解压缩器“,chatGPT确实是一次技术上的飞跃。

相关文章







关于作者

猜你喜欢























