来源:OpenAI
编辑:好困 小咸鱼
【新智元导读】近日,OpenAI训练了一个系统可以解决小学数学问题。一个9-12岁的小孩子在测试中得分为60分,而OpenAI的新方法在同样的问题上可以拿到55分,已经达到了人类小学生90%左右的水平!还记得上小学时,被「口算天天练」里面的应用题绕晕的阴影吗?
来,试一道!
「小明每半小时喝一瓶水。一个普通的数独难题要花他45分钟。一个极难的数独需要4倍的时间。做一道极难的数独那段时间他喝了多少瓶水?」
不算难吧。
但这回,OpenAI要拿这些应用题去考考自家的当家模型,GPT-3。
成绩很喜人啊!
新方法可以解决小学数学问题,60亿参数的GPT-3采用新方法,准确率直接翻倍,甚至追平了1750亿参数,采用微调方法的GPT-3模型。
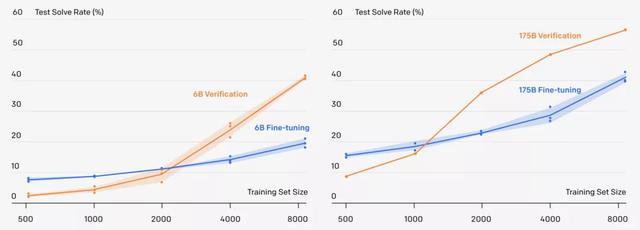
更重要的是,一个9-12岁的小孩子在测试中得分为60分,而采用新方法的GPT-3在同样的问题上可以拿到55分,已经达到了人类小学生90%左右的水平!
偏科的GPT-3:重文轻理
OpenAI的GPT-3以1750亿参数的「大」这一特点,让人印象颇深。GPT-3「文采出众」,上知天文,下知地理。模仿名家的写作风格,展示一下广博的知识,这都不在话下。
然而,GPT-3这种「大」模型却是典型的偏科生,擅长文,但不擅理。
要是指望他们能够完成精确的多步推理,比如,解决小学数学应用题,那还是别指望了。
原因何在?
其实,问题就在于,尽管GPT-3可以模仿正确解决方法的规律,但它经常会在逻辑上产生严重错误。
所以,人类要想教会大语言模型理解复杂的逻辑,就必须得让模型学会识别它们的错误,并仔细选择他们的解题步骤。
传统方法:微调
目前,要想让大模型掌握一个领域,最常用的方法就是用大模型在指定领域微调。
微调通过更新模型参数进行,最小化所有训练token的交叉熵损失。显而易见,1750亿参数的模型性能要优于其他更小的模型。
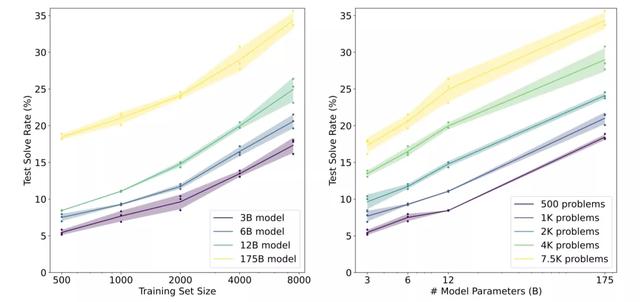
验证器具体训练方法分为「三步走」:
先把模型的「生成器」在训练集上进行2个epoch的微调。从生成器中为每个训练问题抽取100个解答,并将每个解答标记为正确或不正确。在数据集上,验证器再训练单个epoch。「生成器」只训练2个epoch是因为2个epoch的训练就足够学习这个领域的基本技能了。如果采用更长时间的训练,生成的解决方案会过度拟合。
测试时,解决一个新问题,首先要生成100个候选解决方案,然后由「验证器」打分,排名最高的解决方案会被最后选中。
GSM8K数据集有了新的解决方案,再来看看这次考试的「试卷」。
GSM8K由8500个高质量、高多样性、中等难度的小学数学问题组成。当然了。OpenAI表示,对于一个中学生来说,这些问题就都不是问题了。
数据集中的每个问题都需要计算2到8个步骤来得出最终答案,涉及到「加减乘除」四则运算。
高质量:GSM8K中的问题都是人工设计的,避免了错误问题的出现。高多样性:GSM8K中的问题都被设计得相对独特,避免了来自相同语言模板或仅在表面细节上有差异的问题。中等难度:GSM8K中的问题分布对大型SOTA语言模型是有挑战的,但又不是完全难以解决的。这些问题不需要超出早期代数水平的概念,而且绝大多数问题都可以在不明确定义变量的情况下得到解决。自然语言解决方案:GSM8K中的解决方案是以自然语言而不是纯数学表达式的形式编写的。模型由此生成的解决方案也可以更容易被人理解。此外,OpenAI也期望它能阐明大型语言模型内部独白的特性。
6B Fine-tuning:错误

6B Fine-tuning:错误

看来,AI做数学题还是道阻且长啊。
你要不要也来尝试一下?
参考资料:
相关文章








关于作者

猜你喜欢























