关注我们
(本文阅读时间:20分钟)
GPT 是把 Transformer 的解码器提出来,在没有标注的大数据下完成一个语言模型,作为预训练模型,然后在子任务上做微调获得不同任务的分类器。这个逻辑和我们的计算机视觉的套路是一样的。这个模型叫 GPT-1。
GPT-2 收集了更大的数据集,生成了更大的模型这就算 GPT-2,证明了当数据库越大,模型越大,能力就有可能越强,但是需求投入多少钱可以得到预期效果,大家都不确定,所以 GTP-2 没有在市场上获得特别强的反响。
GPT 团队认为自己的算法没有问题,思路没有问题,逻辑没有问题,唯一有问题的就是没有菠菜罐头,所以 GPT 团队找了金主买了菠菜罐头,终于大力水手升级为暴力水手,从大力出奇迹转变为暴力出奇迹,惊艳的 GPT-3 终于诞生了,那么这么暴力升级有多恐怖呢?GPT-3 数据和模型都比 GTP-2 大了100倍!
微软MVP实验室研究员

王豫翔,Leo
微软圈内人称王公子。微软10年 MVP,大龄程序员。目前核心工作是使用微软 AI 技术设计可以落地的解决方案,也就是写 PPT。虽然热爱代码,但只有午夜时分才是自由敲代码的时间。喜欢微软技术,不喜欢无脑照抄。

GPT
关键词:无标注文本、自监督学习、前馈神经网络、自回归模型
GPT全称是 Generative Pre-trained Transformer,名字非常直白,就是生成式预训练转换器。GPT 想解决的问题:在 NLP 领域有很多任务,虽然有了互联网,我们已经可以方便的采集大量的样本,但是相对于有标注的样本,更多存在的是无标注样本,那么我们怎么来使用这些无标注的样本。
GPT 团队的解决方案是在没有标注的样本上训练出一个预训练的语言模型,然后在有标注的特定的子任务上训练一个微调分类器模型。具体来说就是先让模型在大规模无标注数据上针对通用任务进行训练,使模型具备理解语言的基础能力,然后将预训练好的模型在特定的有标注数据上针对下游任务进行微调,使模型能够适应不同的下游任务。
但是 NLP 并不是 AI 中一个新的领域,在之前其实已经有了很多出色的 NLP 模型,那 GPT 的创新在哪里呢?之前的 NLP 模型是和任务绑定的,比如分词,词向量,句子相似度,每一个任务都有自己的模型,所以每一个新任务都需要一个新模型。GPT 的方式是生成一个大模型,然后通过输入的形式就可以获得不同的任务结果。这个是非常创新的思路。
当然了,统一的想法是好的,谁不想要一个这样的统一模型呢?但明显会遇到几个挑战:
损失函数怎么选择,因为在原先的方式中,不同的任务具有不同的损失函数,能不能找到一个损失函数可以为所有任务提供有效服务呢?
NLP 子任务的各自表现形式不同,怎么设计一个表示方式,有没有一种统一的表示可以让所有子任务接受。
在没有标注的文本上训练一个大的语言模型,然后在子任务上进行微调,GPT 称为半监督方式。有大量的无标注的数据和有标注的数据,这些数据具有相似性,那我怎么用我已经标注的数据来有效的使用那些无标注的数据。后来这个方式又叫自监督模型了。
下面是 GPT 提出的解决方案:
无监督预(自监督)训练:在没有标注的数据上做预训练。假设我们有一段文本,里面每一个词都是有序的,GPT 使用了 Transformer 的解码器来预测第一个词出现的概率。预测的方式就是通过前面的词的序列来预测接下来词出现的概率,是不是觉得和我们的联想输入法特别相似,所以前面的词越长,预测出后面词出现的概率精度就越高,这点应该是非常容易理解的。同时我们也可以想象出,这个计算是非常恐怖的。我总觉得 GPT 团队大概很想通过这样的预测模式来预算股票走势。
微调:微调就是输入一段文本,同时给这一段文本设计一个标注,这是一个比较标准的分类手段。GPT 的创新是对这段微调文本同时使用了对下一个词的预测和对完整文本的标签预测。
NLP 的子任务表示形式:NLP 的子任务有很多种,传统 NLP 的任务模型和输入都是对应的,就是一个模型对应一个任务,GPT 要做一个统一模型,就必须定义一个 NLP 子任务的表示形式。
下面的图非常重要,在我看来比论文中各种眼花缭乱的公式重要的多。

分类输入表示:将需要分类的文本在前后加上开始和结束标记,然后放入 Transformer,然后模型对特放进线性层进行微调。
推理输入表示:推理表达是对两段文本给出支持,反对和中立三分类的问题。比如前提为:一个人今年32岁,假设是他未成年,这段的标签就是反对。也能出现前提是:他喜欢吃狗肉。假设是:他不是爱狗人士。如果是我做标签的话,我可能会给出中立的标签。所以微调其实是存在标签设计者者的偏向的。
相似输入表示:两段文本的表达方式不一样,但他们的含义是相似的。由于模型是单向的,但相似度与顺序无关。所以需要将两个句子顺序颠倒后两次输入的结果相加来做最后的推测。
多选题输入表示:给出一个问题和一组答案,预测对这个问题是不是能给出正确答案。
除了无标注文本和自监督学习外,GPT 还有一个创新,这个创新是贯穿了整个 GTP-1-2-3,也是 GPT 和 BERT 的一大区别:GPT 模型既使用了前馈神经网络,又使用了自回归模型,两种模型都在模型的不同部分起到了关键的作用。具体而言,GPT 模型中的编码器部分使用了前馈神经网络和自注意力机制,以将输入序列中的每个单词转换为高维向量表示,并提供上下文信息;而生成器部分则使用了自回归模型,以基于前文生成下一个单词。这两种模型的结合使得 GPT 模型能够更好地处理自然语言和任务,并且在多个任务上取得了非常优秀的表现。
前馈神经网络和自回归的方式都是用来预测下一个单词。它们的不同在于处理输入序列的方式和输出预测的方式。前馈神经网络将整个输入序列一次性传入网络,并在多个全连接层中对其进行转换,最后得到下一个单词的预测。而自回归的方式则是将先前生成的单词作为输入,递归地生成下一个单词,直到达到预设的长度或生成特殊的终止符号为止。
论文出自《Improving Language Understanding by Generative Pre-Training》
链接:https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
GPT-2
关键词:零样本、多任务学习、动态掩码、自适应的词向量权重
据说疾速追杀4马上要上映了,又可以数基努·里维斯杀了多少人了。通常我们都叫疾速追杀1、疾速追杀2、疾速追杀3、疾速追杀4,但其实这部电影的中文名字并不是这样1234,而是疾速追杀、疾速特攻、疾速备战。GPT 也是这样的,GPT-2 的名字其实是Language Models are Unsupervised Multitask Learners,中文的意思是语言模型是无监督的多任务学习器。但我们习惯上还是叫 GPT-2。
在 GPT-1 我们聊过一个事情,传统的 NLP 的任务处理是一个任务收集一个数据集,在这个数据集上构建自己的预测模型。这种方式的优点是目标性比较强,工作量和成本低,大部分团队都可以自己独立去完成自己的目标任务。但是缺点是这个模型的泛化性不够好,一个这样的模型很难被复用到另一个任务上去。
GPT-1 的预训练模型在 GPT-2 团队看来有一个不足的地方,虽然 GPT-1 构建了一个不错的预训练模型,但是对下游任务还是需要使用有标注的样板来训练新的模型,也就是说需要对具体的下游任务做有监督的微调。GPT-1 的有监督微调就是我们之前说的输入表示。这样下游任务还是需要先训练一个模型,这样下游任务才能了解输入的表示,比如开头,结尾,分隔符,所以很明显下游任务需要做两个事情:收集一些有标签的样本,同时训练一个可以理解这些样本的模型。
所以 GPT-2 团队计划继续优化语言模型,并且用 Zero-Shot(零样本)让下游任务不再需要接受任何有标注的样本。既然不再需要那些标记,那么也就不需要构建新的模型了。
这个 Zero-Shot(零样本)使得下游任务可以不需要接受有标注的样本,也不需要构建新的模型,是 GTP-2 最重要的创新和绝对大胆的尝试。怎么使得预训练模型具备此能力呢?要从预训练过程入手,GPT-2 团队参考了上世纪的一个观点:多任务学习,同时看多个数据集,用多个损失函数让模型在多个任务上可以用。那么下游任务不做新的模型,也不接受有特定标记的输入,那怎么样能让下游任务可以理解输入呢?
GPT-2 说他的语言模式可以接受自然语言对任务的请求,在论文中他给出了两个案例:
一个是描述翻译任务:translate to french, english text, french text
一个是描述问答任务:answer the question, document, question, answer
要实现这样的效果,GPT-2 团队认为需要一个非常大的模型,需要非常大的数据。GPT-1 采用了7000本没有公开发布的书做数据集,那现在 GPT-2 团队就要解决能满足自己目标的高质量数据集哪里来。
GPT-2 瞄准了 Reddit。这个网站中文叫红迪网,是一个娱乐、新闻和社交网站,是美国第五大网站,流量仅次于 Google、YouTube、Facebook 以及 Amazon。Reddit 中的社区被称为 subreddit(简称 sub),按照不同的主题内容来分类,包括新闻、游戏、音乐、健身、食物和图片共享等。你可以认为类似贴吧,知乎,豆瓣,小红书的综合体。注册用户可以在上面发布文字、图像或链接,然后由其他成员投票赞成或反对,结果将被用来进行排名和决定它在首页或子页的位置。
每位用户都可以创建 sub ,创建者就是 sub 的 mod(即管理者),mod 权限很大,能够决定一个 sub 的风格和规则。用户(也叫 redditors)能够浏览各类社区,可以提交内容链接或发布原创,可以支持、反对、评论、转发帖子,用户发布的优质有趣内容可以获得帖子分数(post karma)及留言分数(comment karma),甚至能够获赠 Reddit 硬币。和其他社交网站不同,Reddit 的匿名性使其不存在任何自带流量的 KOL,所有内容完全按照热度排名,热门内容会被推到首页。所以 GPT-2 团队认为,这样一个由人群自发进行过滤选择的内容网站就是一个天然的被标注了内容优劣的样本,而且还对知识类型做了分类。那么如何提取出这个社区里面优质内容呢?GPT-2 团队选择了 Reddit 中具有三个以上 Karma 的帖子。Karma 是你在 Reddit 所得的分数,表示你所发表的帖子在社区里所占有的价值量。每个用户在 Reddit 都有他们自己的评论 Karma 和链接 Karma。相当于你在 Reddit 的等级标志。每个人拥有2组 Karma 值,分别为发布 Karma 和评论 Karma,分别对应内容发布和内容评论。原则上,收到一个顶就 1,收到一个踩就-1,但是同时在同一篇内容所获得的顶踩值会有衰减效应,即当你获得的点赞越多,每个点赞兑现的 karma 值越低。所以 Reddit 的这个相对公平的设置真的是天然的从大众的价值观对内容进行了分类和优劣评价,这就是 GPT-2 团队所需要的。最后 GPT-2 团队从 Reddit 中爬取了4500万链接,800万篇文档,一共40G文本。
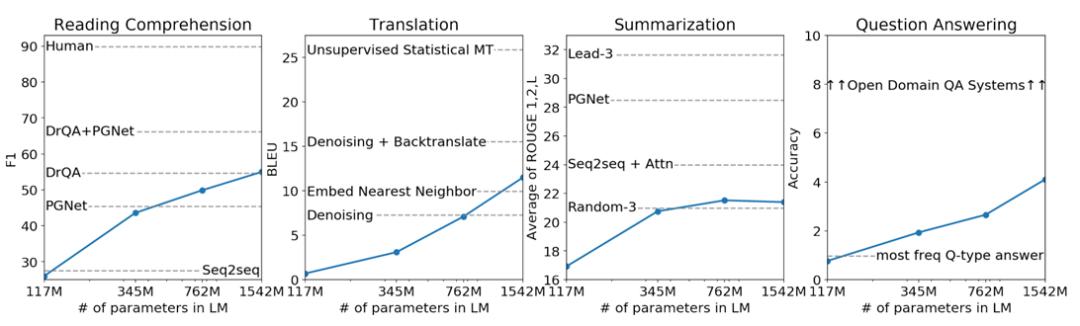
基于这些数据集,GPT-2 团队设计了四个模型:
参数
层
模型
1.17亿
12
768M
3.45亿
24
1024M
7.62亿
36
1280M
15.42亿
48
1600M
GPT-2 团队非常实诚的对这四个模型分别在阅读理解,翻译,摘要和问答四个领域和当时最主流的模型做了 PK。
微软最有价值专家是微软公司授予第三方技术专业人士的一个全球奖项。30年来,世界各地的技术社区领导者,因其在线上和线下的技术社区中分享专业知识和经验而获得此奖项。
MVP是经过严格挑选的专家团队,他们代表着技术最精湛且最具智慧的人,是对社区投入极大的热情并乐于助人的专家。MVP致力于通过演讲、论坛问答、创建网站、撰写博客、分享视频、开源项目、组织会议等方式来帮助他人,并最大程度地帮助微软技术社区用户使用 Microsoft 技术。
更多详情请登录官方网站:
https://mvp.microsoft.com/zh-cn
谢谢你读完了本文
喜欢可转发到朋友圈
也欢迎随时来后台跟我聊天
输入“@D姐” 呼唤我哦!

*未经授权请勿私自转载此文章及图片
如有转载需求,可后台私信或留言,谢谢
相关文章









关于作者

猜你喜欢























