机器之心报道
机器之心编辑部
ChatGPT 点燃了科技行业的明灯,GPT-4 能燎原吗?
谁能革得了 ChatGPT 的命?现在看来还是 OpenAI 自己。
在 ChatGPT 引爆科技领域之后,人们一直在讨论 AI「下一步」的发展会是什么,很多学者都提到了多模态,我们并没有等太久。今天凌晨,OpenAI 发布了多模态预训练大模型 GPT-4。

「GPT-4 是世界第一款高体验,强能力的先进AI系统,我们希望很快把它推向所有人,」OpenAI 工程师在介绍视频里说道。
似乎是想一口气终结这场游戏,OpenAI 既发布了论文(更像是技术报告)、 System Card,把 ChatGPT 直接升级成了 GPT-4 版的,也开放了 GPT-4 的 API。
另外,微软营销主管在 GPT-4 发布后第一时间表示:「如果你在过去六周内的任何时候使用过新的 Bing 预览版,你就已经提前了解了 OpenAI 最新模型的强大功能。」是的,微软的新必应早就已经用上了GPT-4。


就像许多使用 ChatGPT 的公司一样,OpenAI 表示他们内部也在使用 GPT-4,因此 OpenAI 也在关注大型语言模型在内容生成、销售和编程等方面的应用效果。OpenAI 还使用 GPT-4 辅助人们评估 AI 输出,这也是 OpenAI 对其策略的第二阶段。OpenAI 既是 GPT-4 的开发者,也是使用者。
GPT-4:我能玩梗图
GPT-4 可以接受文本和图像形式的 prompt,新能力与纯文本设置并行,允许用户指定任何视觉或语言任务。
具体来说,它在人类给定由散布的文本和图像组成的输入的情况下生成相应的文本输出(自然语言、代码等)。在一系列领域 —— 包括带有文本和照片的文档、图表或屏幕截图上 ——GPT-4 展示了与纯文本输入类似的功能。此外,它还可以通过为纯文本语言模型开发的测试时间技术得到增强,包括少样本和思维链 prompt。
比如给 GPT-4 一个长相奇怪的充电器的图片,问为什么这很可笑?

格鲁吉亚和西亚的人均每日肉类消费,算平均数:

看起来,现在的 GPT 已经不会在计算上胡言乱语了:

GPT-4 看懂了法语题目,并完整解答:

GPT-4 可以理解一张照片里「有什么不对劲的地方」:

它给出了详细的回答:

局限性
尽管功能已经非常强大,但 GPT-4 仍与早期的 GPT 模型具有相似的局限性,其中最重要的一点是它仍然不完全可靠。OpenAI 表示,GPT-4 仍然会产生幻觉、生成错误答案,并出现推理错误。
目前,使用语言模型应谨慎审查输出内容,必要时使用与特定用例的需求相匹配的确切协议(例如人工审查、附加上下文或完全避免使用) 。
总的来说,GPT-4 相对于以前的模型(经过多次迭代和改进)已经显著减轻了幻觉问题。在 OpenAI 的内部对抗性真实性评估中,GPT-4 的得分比最新的 GPT-3.5 模型高 40%:

该模型在其输出中可能会有各种偏见,OpenAI 在这些方面已经取得了进展,目标是使建立的人工智能系统具有合理的默认行为,以反映广泛的用户价值观。
GPT-4 通常缺乏对其绝大部分数据截止后(2021 年 9 月)发生的事件的了解,也不会从其经验中学习。它有时会犯一些简单的推理错误,这似乎与这么多领域的能力不相符,或者过于轻信用户的明显虚假陈述。有时它也会像人类一样在困难的问题上失败,比如在它生成的代码中引入安全漏洞。
GPT-4 预测时也可能出错但很自信,意识到可能出错时也不会 double-check。有趣的是,基础预训练模型经过高度校准(其对答案的预测置信度通常与正确概率相匹配)。然而,通过 OpenAI 目前的后训练(post-training)过程,校准减少了。

训练过程
与之前的 GPT 模型一样,GPT-4 基础模型经过训练可以预测文档中的下一个单词。OpenAI 使用公开可用的数据(例如互联网数据)以及已获得许可的数据进行训练。训练数据是一个网络规模的数据语料库,包括数学问题的正确和错误解决方案、弱推理和强推理、自相矛盾和一致的陈述,以及各种各样的意识形态和想法。
因此,当提出问题时,基础模型的回应可能与用户的意图相去甚远。为了使其与用户意图保持一致,OpenAI 依然使用强化学习人类反馈 (RLHF) 来微调模型的行为。请注意,该模型的能力似乎主要来自预训练过程 ——RLHF 不会提高考试成绩(甚至可能会降低它)。但是模型的控制来自后训练过程 —— 基础模型甚至需要及时的工程设计来回答问题。
GPT-4 的一大重点是建立了一个可预测扩展的深度学习栈。主要原因是,对于像 GPT-4 这样的大型训练,进行广泛的特定模型调整是不可行的。团队开发了基础设施和优化,在多种规模下都有可预测的行为。为了验证这种可扩展性,他们提前准确地预测了 GPT-4 在内部代码库(不属于训练集)上的最终损失,方法是通过使用相同的方法训练的模型进行推断,但使用的计算量为 1/10000。

现在,OpenAI 可以准确地预测在训练过程中优化的指标(损失)。例如从计算量为 1/1000 的模型中推断并成功地预测了 HumanEval 数据集的一个子集的通过率:
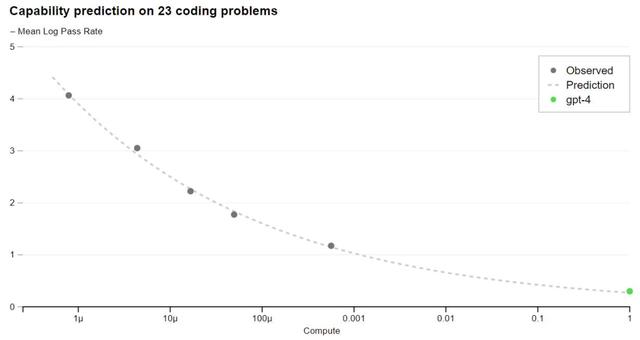
有些能力仍然难以预测。例如,Inverse Scaling 竞赛旨在找到一个随着模型计算量的增加而变得更糟的指标,而 hindsight neglect 任务是获胜者之一。GPT-4 扭转了这一趋势。

能够准确预测未来的机器学习能力对于技术安全来说至关重要,但它并没有得到足够的重视,OpenAI 表示正在投入更多精力开发相关方法,并呼吁业界共同努力。
OpenAI 表示正在开源 OpenAI Evals 软件框架,它被用于创建和运行基准测试以评估 GPT-4 等模型,同时可以逐样本地检查模型性能。
ChatGPT 直接升级至 GPT-4 版
GPT-4 发布后,OpenAI 直接升级了 ChatGPT。ChatGPT Plus 订阅者可以在 chat.openai.com 上获得具有使用上限的 GPT-4 访问权限。
要访问 GPT-4 API(它使用与 gpt-3.5-turbo 相同的 ChatCompletions API),用户可以注册等待。OpenAI 会邀请部分开发者体验。
获得访问权限后,用户目前可以向 GPT-4 模型发出纯文本请求(图像输入仍处于有限的 alpha 阶段)。至于价格方面,定价为每 1k 个 prompt token 0.03 美元,每 1k 个 completion token 0.06 美元。默认速率限制为每分钟 40k 个 token 和每分钟 200 个请求。
GPT-4 的上下文长度为 8,192 个 token。OpenAI 还提供了 32,768 个 token 上下文(约 50 页文本)版本的有限访问,该版本也将随着时间自动更新(当前版本 gpt-4-32k-0314,也支持到 6 月 14 日)。定价为每 1K prompt token 0.06 美元和每 1k completion token 0.12 美元。
以上,就是今天 OpenAI 关于 GPT-4 的所有内容了。令人不满的一点是,OpenAI 公开的技术报告中,不包含任何关于模型架构、硬件、算力等方面的更多信息,可以说是很不 Open 了。
不管怎样,迫不及待的用户大概已经开始测试体验了吧。
最后,也想问一下读者,看完 GPT-4 的发布,你有何感想。
相关文章









关于作者

猜你喜欢























