编辑部 发自 凹非寺量子位 | 公众号 QbitAI
GPT-4发布一天之后,压力全部给到百度这边。
就在刚刚,百度交卷。
文心一言,百度全新一代知识增强大语言模型,正式在百度总部“挥手点江山”会议室里发布。
在一片静寂的氛围里,李彦宏小步登场,语气里带着点紧张:
大家的期望值,是我们对标ChatGPT,对标GPT-4,这个门槛有点高(笑)。
十月怀胎,我们就带大家来看看这个AI大模型文心一言长什么样。

再来看看GPT-4起名的效果?

看起来,GPT-4对中文的掌控能力相比之下还是少了一点精髓。
至于写个公司成立的新闻稿?对文心一言来说似乎也不成问题:
 数理逻辑推算
数理逻辑推算数学能力,是考验生成式大模型的一大难题。ChatGPT刚上线时,也翻了不少车。
不过在现场,文心一言处理的数学问题不算复杂,是小学数学竞赛常见的鸡兔同笼问题。

彩蛋是,李彦宏现场展示的第一题,引得文心一言说出了《狂飙》里高启盛的经典台词:这题出得不对。

诶,看起来反而是GPT-4没有真正理解“藏头诗”的含义。
这波文化理解上,属实是文心一言“小胜一筹”了。
不过在英文上,李彦宏也承认,虽然文心一言也能处理,但能力是显著不如中文的。
这也和百度目前能用到的训练数据有关。
多模态生成最后,李彦宏还简单展示了一下文心一言多模态生成的能力。
首先来看看,为即将到来的2023世界智能交通大会创作海报——

首先来看与ChatGPT类似的技术:有监督精调、RLHF和提示构建。
有监督精调,尤其指中文方面的数据精调。百度基于对中国语言文化和中国应用场景的理解,筛选了特定的数据来训练模型。

至于人类反馈的强化学习(RLHF)和提示构建,操作上也与ChatGPT大差不差。

随后是百度提出的、用于进一步改善模型效果的技术。
知识增强,包括知识内化和知识外用两个部分。其中,知识内化即将知识“渗透”进模型参数中;知识外用指的是模型可以直接使用外部的知识。

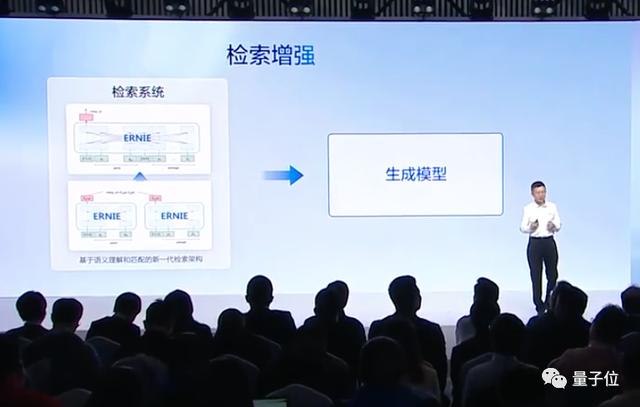
检索增强,则与百度搜索引擎积累的检索技术有关。
百度将把检索技术和生成技术结合起来,先对内容进行检索后,将比较有用的部分用于生成,再整合输出结果:
概括来看,文心一言表现出的能力,被李彦宏称为“智能涌现”:
当参数达到千亿量级,训练语料达到足够多的情况下,这种现象就会发生。
目前,百度拥有的AI技术可以分为四个部分,芯片(昆仑芯)、框架(飞桨)、模型(文心)和应用。
之所以软硬件都要布局,百度称,是为了降低成本:
生成式AI需求的算力非常高,费用相当昂贵。
因此,如果在四层架构之间相互进行协同优化,就能让它的效率比别人更高,从而显著降低成本。
李彦宏认为,这也正是百度的优势所在:
四层都有领先产品的公司,绝无仅有。

对于这一点,李彦宏的解释是,给出的问题都比较长,为了节约现场时间,所以才用了提前录制的形式。
还有不少网友对文心一言展示出的能力不太满意。有人调侃,看完之后感觉“提前退休的日子看起来还可以缓一缓”:

不过也有网友表示,希望能给国产产品一点时间一点耐心。

发布会末尾,王海峰宣布,文心一言将从今天开始对外进行测试,包括个人用户和企业用户。
是骡子是马,相信接下来,会得到更多验证。
One More Thing对了,有网友表示,已经拿到了文心一言的内测资格:
你好,感谢您体验文心一言,体验地址: https://yiyan.baidu.com/welcome,希望您在体验当中给予更多意见,文心一言邀请码:KFCVME50RMB,2023年3月16日24:00前有效。
嗯,万物疯狂星期四(手动狗头)。
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
相关文章









关于作者

猜你喜欢























