作者 | 张俊林 责编 | 王子彧
出品 | CSDN(ID:CSDNnews)
如今,大语言模型已经彻底改变了自然语言处理 (NLP)的研发现状。众所周知,增加语言模型的规模能够为一系列下游 NLP 任务带来更好的任务效果,当模型规模足够大的时候,大语言模型会出现涌现现象,就是说突然具备了小模型不具备的很多能力。
本文整理自 3 月 11 日 「ChatGPT 及大规模专题研讨会」上,来自新浪微博新技术研发负责人张俊林《大型语言模型的涌现能力:现象与解释》的分享,介绍了大语言模型中的涌现现象,以及关于涌现能力背后原因的相关猜想。

什么是大模型的涌现能力
复杂系统中的涌现现象
复杂系统学科里已经对涌现现象做过很久的相关研究。那么,什么是“涌现现象”?当一个复杂系统由很多微小个体构成,这些微小个体凑到一起,相互作用,当数量足够多时,在宏观层面上展现出微观个体无法解释的特殊现象,就可以称之为“涌现现象”。

第三类任务数量较少,随着模型规模增长,任务效果体现出一个 U 形曲线。如上图所示,随着模型规模增长,刚开始模型效果会呈下降趋势,但当模型规模足够大时,效果反而会提升。如果对这类任务使用思维链 CoT 技术,这些任务的表现就会转化成伸缩法则,效果也会随着模型规模增长而持续上升。因此,模型规模增长是必然趋势,当推进大模型规模不断增长的时候,涌现能力的出现会让任务的效果更加出色。

目前有两大类被认为具有涌现能力的任务,第一类是 In Context Learning(“Few-Shot Prompt”),用户给出几个例子,大模型不需要调整模型参数,就能够处理好任务(参考上图给出的情感计算的例子)。

如上图展示,利用 In Context Learning,已经发现在各种类型的下游任务中,大语言模型都出现了涌现现象,体现在在模型规模不够大的时候,各种任务都处理不好,但是当跨过某个模型大小临界值的时候,大模型就突然能比较好地处理这些任务。
第二类具备涌现现象的技术是思维链 (CoT)。CoT 本质上是一种特殊的 few shot prompt,就是说对于某个复杂的比如推理问题,用户把一步一步的推导过程写出来,并提供给大语言模型(如下图蓝色文字内容所示),这样大语言模型就能做一些相对复杂的推理任务。

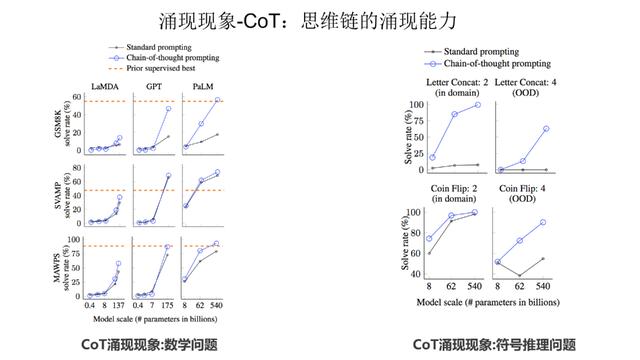
LLM 模型规模和涌现能力的关系
可以看出,涌现能力和模型的规模大小有一定的关联关系 ,那么,我们的问题是,具体而言,两者是怎样的关系呢?

第一个小模型代表,是 DeepMind 2021 年发表的模型 Chinchilla,这个模型目前做各种任务的效果,和 540B 大小的 PaLM 基本相当。Chinchilla 的思路是给更多的数据,但是把模型规模做小。具体而言,它对标的是 Gopher 模型,Chinchilla 模型大小只有 70B,是 Gopher 的四分之一,但是付出的代价是训练数据总量,是 Gopher 的四倍,所以基本思路是通过放大训练数据量,来缩小模型规模。
我们把 Chinchilla 规模做小了,问题是它还具备涌现能力吗?从上图给出的数据可以看出,起码我们可以说,Chinchilla 在自然语言处理的综合任务 MMLU 上是具备涌现能力的。如果小模型也能具备涌现能力,那么这其实侧面反映了一个问题:对于类似 GPT3 这样的模型而言,很可能它 175B 这么多的模型参数,并没有被充分利用,因此,我们在以后训练模型的时候,可以考虑先增加训练数据,降低模型参数量,把模型做小,先把模型参数利用充分,在这个基础上,再继续增加数据,并推大模型规模。也即是说,目前看,我们先把模型做小,再把模型做大,看上去是可行的。

首先,第一个事实是 Grokking 现象是描述训练数据量较少的 ML 任务的,但是任务最小训练数据量必须达到一定的量,才会出现 Grokking 现象。这里有两点,一个是本身训练数据量少,另外是最小数据量要达到临界值。只有同时满足上面两个条件,才有可能出现 Grokking 现象。上图的意思是:当我们只拿40% 及以下比例的数据来训练模型的时候,我们看不到 Grokking 现象,只有记忆没有泛化,只有最小训练数据比例超过 40%,才会出现模型的顿悟。这是一个已被验证的事实。

第二个事实是 LLM 模型规模越大,记忆数据的能力越强。关于这点目前有很多研究已经可以证明,如果简单理解的话,可以理解为:对于某个任务 T,假设预训练数据里包含与任务 T 相关的训练数据量有 100 条,那么大模型可以记住其中的 70 条,而小模型可能只能记住 30 条。虽不精确,但大概是这个意思。
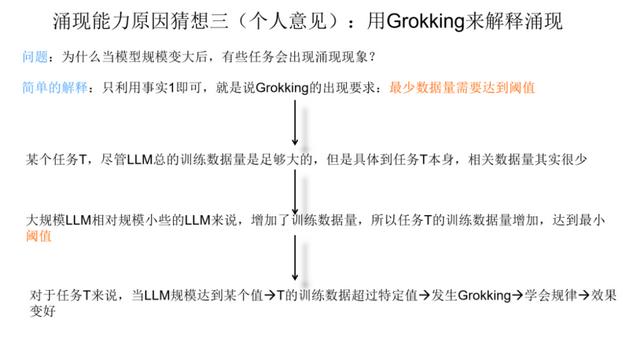
在上面的两个事实基础上,我们试图来用 Grokking 解释大模型的涌现现象。首先我们给出一个简单的解释,这个解释只需要利用第一个事实即可,就是说,任务的最少训练数据量需要达到临界值,才会出现 Grokking。在这个事实下,对于某个任务 T,尽管我们看到的预训练数据总量是巨大的,但是与 T 相关的训练数据其实数量很少。当我们推大模型规模的时候,往往会伴随着增加预训练数据的数据量操作,这样,当模型规模达到某个点的时候,与任务 T 相关的数据量,突然就达到了最小要求临界点,于是我们就看到了这个任务产生了 Grokking 现象。在语言模型的宏观角度,看起来就是模型达到了某个规模,突然任务 T 效果就开始变好,而模型规模较小的时候,因为没有达到临界值,所以一直没有 Grokking 现象,看起来就是语言模型没有这个能力。这是一种可以从 Grokking 角度解释大模型涌现现象的可能。

上面这个猜想其实有个约束条件,因为我们有个假设,说随着模型规模增大,训练数据量也在增大。如果这个假设不存在,也就是说,随着模型规模增大,我们固定住训练数据量不变。那么,这种情况下,怎么能用 Grokking 解释涌现现象呢?此时如果我们同时利用事实 1 和事实 2,也可以给出一个解释。更具体来说,我们假设在预训练数据中,某个任务 T 有 100 个训练数据,当模型规模小的时可能只记得 30 个,达不到 Grokking 现象的临界点,而当模型规模推大时,因为模型记忆能力增强,可能就能记住其中的 50 个,这意味着它可能超过了 Grokking 的临界点,于是会出现 Grokking 里面的泛化现象。如果从这个角度看,其实我们也可以从 Grokking 角度来解释为何只有大模型才会具备涌现现象。
作者简介
张俊林,中国中文信息学会理事,目前是新浪微博新技术研发负责人。博士毕业于中科院软件所,主要的专业兴趣集中在自然语言处理及推荐搜索等方向,喜欢新技术并乐于做技术分享,著有《这就是搜索引擎》,《大数据日知录》,广受读者好评。
相关文章









关于作者

猜你喜欢























